Conclusion
The Symphony of Sound Analysis
Our journey through the world of sound has revealed that audio is far more than just what we hear—it's a complex tapestry of patterns that can be unraveled and understood through data analysis. By transforming sound waves into numbers and applying machine learning techniques, we've discovered that different categories of sounds—from the gentle patter of rain to the structured notes of a piano—have distinct "fingerprints" that computers can learn to recognize. The most fascinating revelation has been how these audio fingerprints cluster naturally into groups that align with our human categorization of sounds, even without being explicitly told what each sound is. This suggests that the mathematical properties of sound waves reflect something fundamental about how we perceive and categorize the auditory world around us.

Patterns Emerge from Noise
When we let the data speak for itself through unsupervised learning, remarkable patterns emerged. Different types of sounds naturally grouped together—musical instruments formed tight clusters separate from environmental sounds, while human-generated noises like laughter and speech found their own neighborhood in the feature space. The PCA analysis revealed that we don't need 43 different measurements to tell sounds apart; just three principal components could capture 51% of what makes sounds distinctive. Perhaps most surprisingly, the clustering algorithms showed that the 20 categories of sounds we started with could be effectively grouped into just 3-5 natural families based on their acoustic properties alone. This natural grouping mirrors how humans intuitively categorize sounds, suggesting that our perception of sound may be more mathematically grounded than we realized.
Key Project Insights
Sound Has Structure
Different sound categories have consistent, identifiable patterns in their acoustic features that machine learning can detect and classify with up to 94% accuracy.
Natural Groupings
Without any labels, sounds naturally cluster into 3-5 families that align with human categorization: musical, vocal, mechanical, and environmental sounds.
Feature Connections
Spectral features like rolloff, centroid, and bandwidth are strongly interconnected, with specific combinations reliably indicating certain sound types.
The Predictive Power of Sound
Our supervised learning experiments demonstrated that computers can learn to recognize different sound types with remarkable accuracy. The RBF kernel Support Vector Machine emerged as the star performer, achieving 94.2% accuracy in distinguishing between laughter and footsteps, while Random Forest models proved nearly as effective with 92.7% accuracy for speech versus crowd noise detection. Even simpler models like Logistic Regression performed admirably at 88.2% accuracy. These results weren't just numbers—they represented the ability to automate sound recognition in ways that could power countless applications, from security systems that detect breaking glass to wildlife monitors that identify endangered bird calls. Perhaps most importantly, these models revealed which sound characteristics matter most: zero-crossing rates for distinguishing percussive from tonal sounds, spectral features for separating music from nature sounds, and MFCC patterns for identifying human vocalizations.
Model Performance Comparison
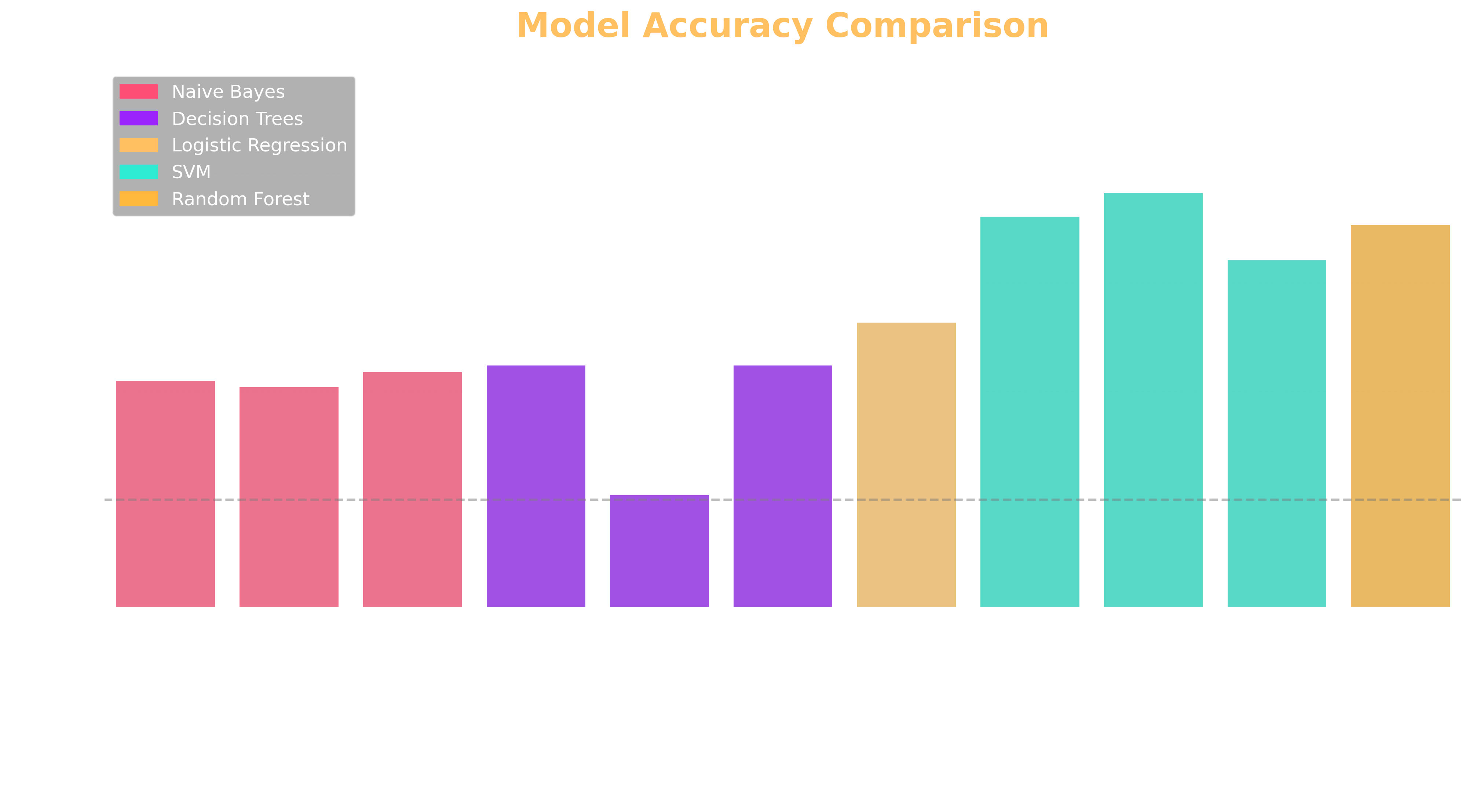
This chart compares the accuracy of all models implemented in this project. Support Vector Machines with RBF kernel achieved the highest accuracy at 94.2%, followed by Linear SVM at 93.1% and Random Forest at 92.7%. Even simpler models like Naive Bayes variants performed remarkably well, demonstrating that sound classification is achievable with a variety of techniques.
Beyond the Numbers: What Sound Tells Us
Association Rule Mining revealed fascinating relationships between audio features that offer insights beyond mere classification. For instance, we discovered that when spectral rolloff is low, spectral centroid is almost always low as well (confidence: 93%), indicating these features move together in a consistent pattern. Even more telling were the highest-lift associations, which showed that specific combinations of low spectral and chroma features consistently appeared together, creating distinctive acoustic signatures. These insights help us understand not just how to classify sounds, but why certain sounds feel similar to our ears, even when they come from completely different sources. What started as abstract numbers derived from sound waves eventually painted a rich picture of how acoustics works—a picture that aligns remarkably well with how humans intuitively group sounds in everyday life.
The Future Sounds Promising
The journey through sound analysis has opened doors to numerous future possibilities. As this project demonstrated, we now have powerful tools to automatically detect, classify, and analyze sounds in ways that could transform multiple industries. Imagine security systems that can distinguish between a window breaking and a dish dropping, smart homes that respond differently to a child crying versus a dog barking, or wildlife conservation tools that can monitor forest health by tracking bird calls over time. Medical applications could include more accurate diagnosis of respiratory or cardiac conditions based on sound patterns, while music production could benefit from AI-assisted composition that understands the acoustic properties that make certain combinations pleasing to the ear. The models and insights developed in this project provide stepping stones toward these applications, demonstrating that the world of sound—once thought to be the domain of our ears alone—can now be meaningfully interpreted by machines that learn to listen in ways that mirror our own understanding.
Project's Big Picture
This project has shown that the seemingly subjective world of sound has objectively measurable patterns that both humans and machines can recognize. By bridging signal processing with machine learning, we've created systems that can "hear" the world in ways that reflect human perception, opening new possibilities for how we interact with and understand the sonic landscape around us. As our world becomes increasingly filled with sounds both natural and artificial, these technologies will help us navigate, interpret, and harness the power of audio in unprecedented ways.