Data Exploration
Data Collection
Our data source was steam reviews which were collected using Steam’s GetAppReviews API. Using the API we fetched 1500 reviews per game, in batches of 100 reviews per API call, for a total of around 45000 reviews to work with. We selected a diverse set of 30 games, both with and without adjustable difficulty settings, from a variety of genres like RPG, shooters, puzzle, simulation, etc. The full list of games is below:
- Elden Ring (RPG/Action)
- Sekiro: Shaodws Die Twice (Action/Adventure)
- Dark Souls Remastered (RPG/Action)
- Armored Core VI: Fires of Rubicon (Mech Combat/Action)
- Hollow Knight (Metroidvania/Platformer)
- Hades (Roguelike/Action)
- Dead Cells (Roguelike/Metroidvania)
- Slay the Spire (Roguelike/Deckbuilding)
- Returnal (Third-Person Shooter/Roguelite)
- Risk of Rain 2 (Action/Roguelike)
- The Witcher 3 (Open World/RPG)
- Mass Effect Legendary Edition (Third-Person Shooter/RPG)
- Divinity: Original Sin 2 (Tactical RPG)
- Baldur's Gate 3 (Turnbased/RPG)
- Pillars of Eternity (Isometric RPG)
- Portal 2 (Puzzle/Platformer)
- The Witness (Puzzle/Exploration)
- Celeste (Platformer/Adventure)
- Ori and the Blind Forest (Platformer/Metroidvania)
- INSIDE (Puzzle/Adventure)
- Stardew Valley (Farming/Life Simulation)
- Factorio (Automation/Management)
- Frostpunk (Survial/City Building)
- The Forest (Survival/Adventure)
- Subnautica (Exploration/Survival)
- Call of Duty: Modern Warfare (Tactical FPS)
- Rocket League (Sports/Competitive)
- Counter-Strike 2 (FPS/Competitive)
- Team Fortress 2 (Multiplayer FPS)
- Dota 2 (MOBA/Competitive)
The API returns the reviews in JSON Format. The raw review data for each game looks something like this:
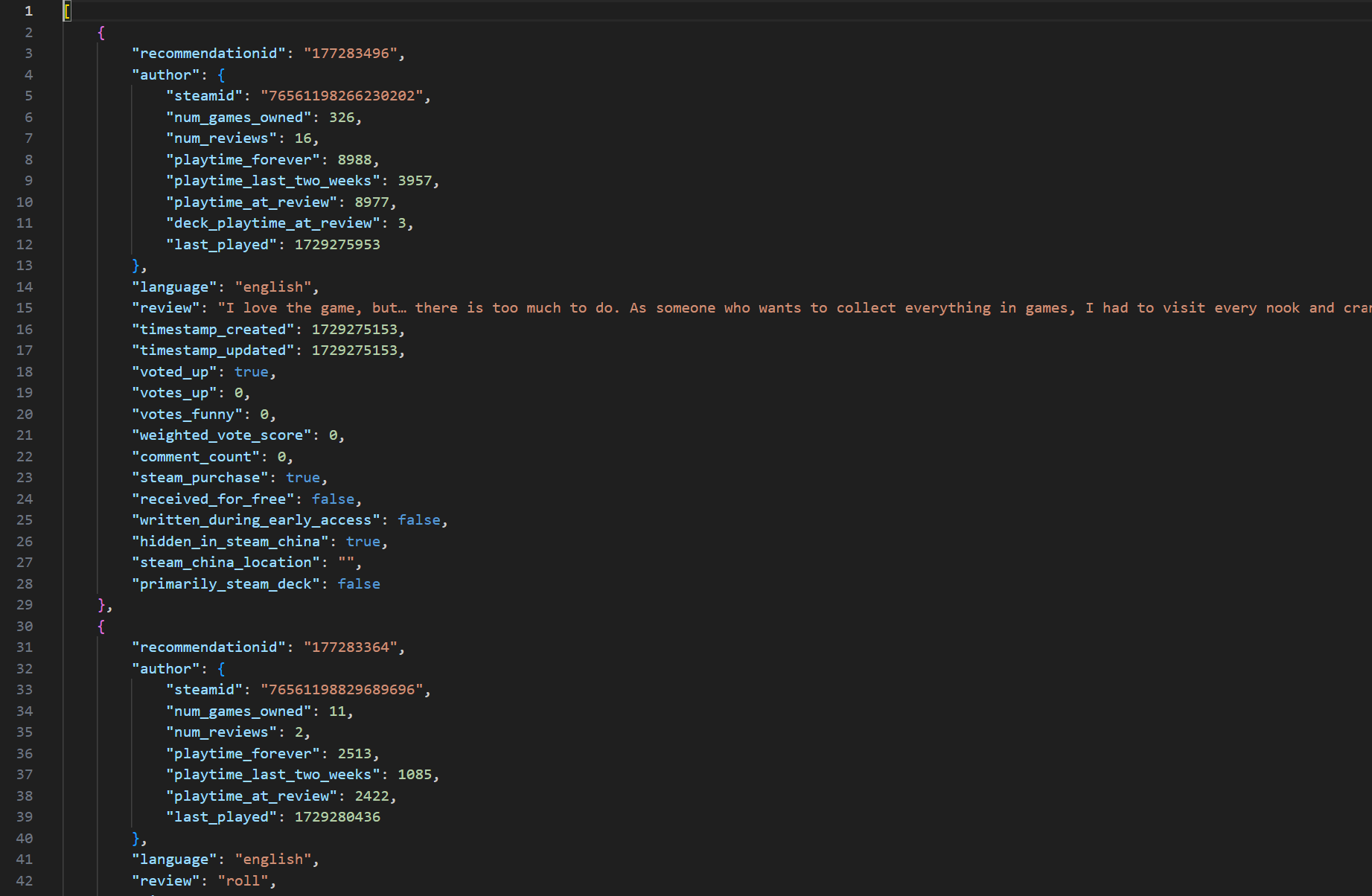
Data Preprocessing
Reviews from each game were stored in JSON Files. First, we compiled all JSON files into one single pandas dataframe for data preprocessing. Any duplicate or non english records were removed. A field called “author” was a dictionary, which was flattened by appending each of its keys as a separate column in the dataframe. Records without “playtime_at_review” fields were dropped. For our analysis we would only need the columns: "game_name", "review", "voted_up", "timestamp_created", "author_num_games_owned", "author_num_reviews", "author_playtime_at_review", "author_playtime_last_two_weeks" and "author_playtime_forever". Only these relevant columns were kept with others getting discarded. The "review" column was cleaned with all text being converted to lowercase for uniformity, punctuation and non alphanumeric characters were removed using regular expressions. We also filter out reviews with lack of meaningful content. We do this by first checking if the review has "valid words". "Valid words" are defined to be meaningful english words. But some terms which are commonly used in gaming scenarios like "gg", "goty", "despawn", etc. are also added to our set of valid words. However, we cannot manually add all words relevant to the games and there could still be words which are specific to some games and their communities like the word "elden" used in the game Elden Ring. So, we add another check in our validation such that if a word, which isn't already marked valid by our inital check, appears more than 3 times across other reviews is marked as a valid words. With these checks, the reviews are marked as relevant only if atleast 50% of the words are found to be valid. All records with empty or irrelevant reviews after the transformations were dropped with the dataset now having close to 43000 records. The cleaned dataset is stored in a csv which looks like this:
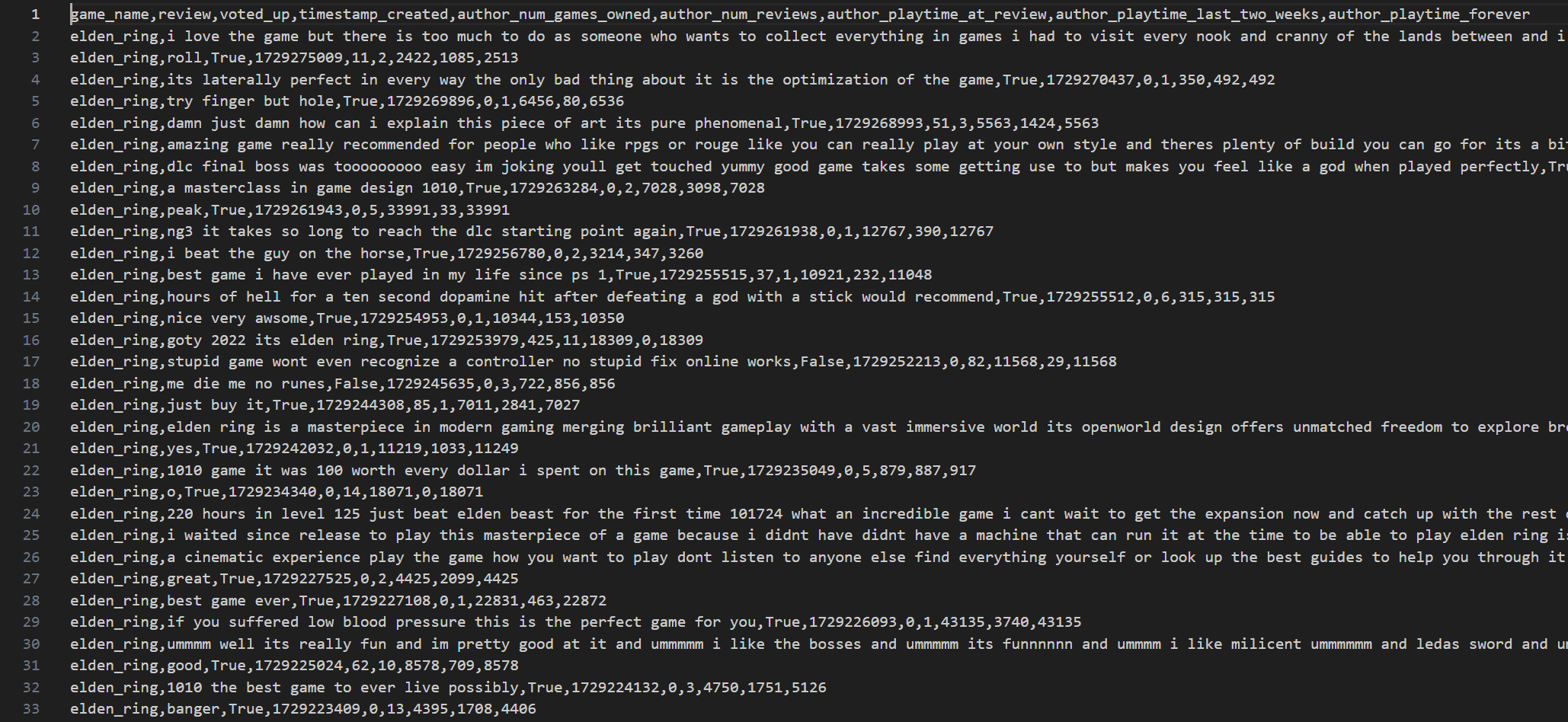
For a detailed walkthrough of our data collection and preprocessing step, you can view our full Jupyter notebook here.
Initial Data Exploration and Visualizations
First we look at some inital data exploration. We load our cleaned reviews dataset into a pandas dataframe df. The columns along with their data types look like this:
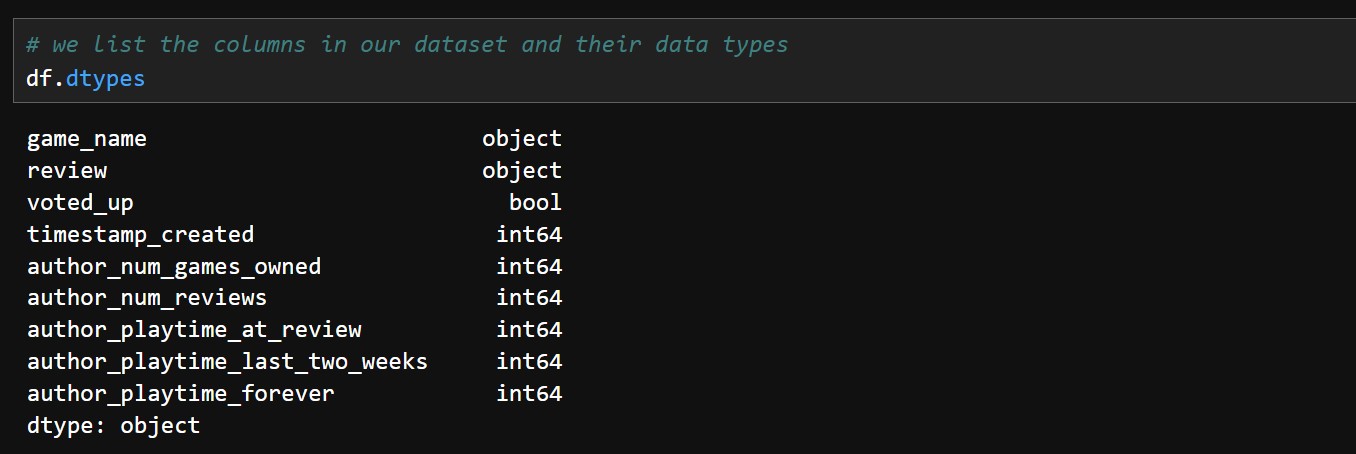
We have 9 columns, with game_name and the review being objects (string), the voted_up which indicates if the review was positive or negative being boolean, and all our columns with information about the author of the review being numerical. We can then get a summary of all numerical columns of our dataset:
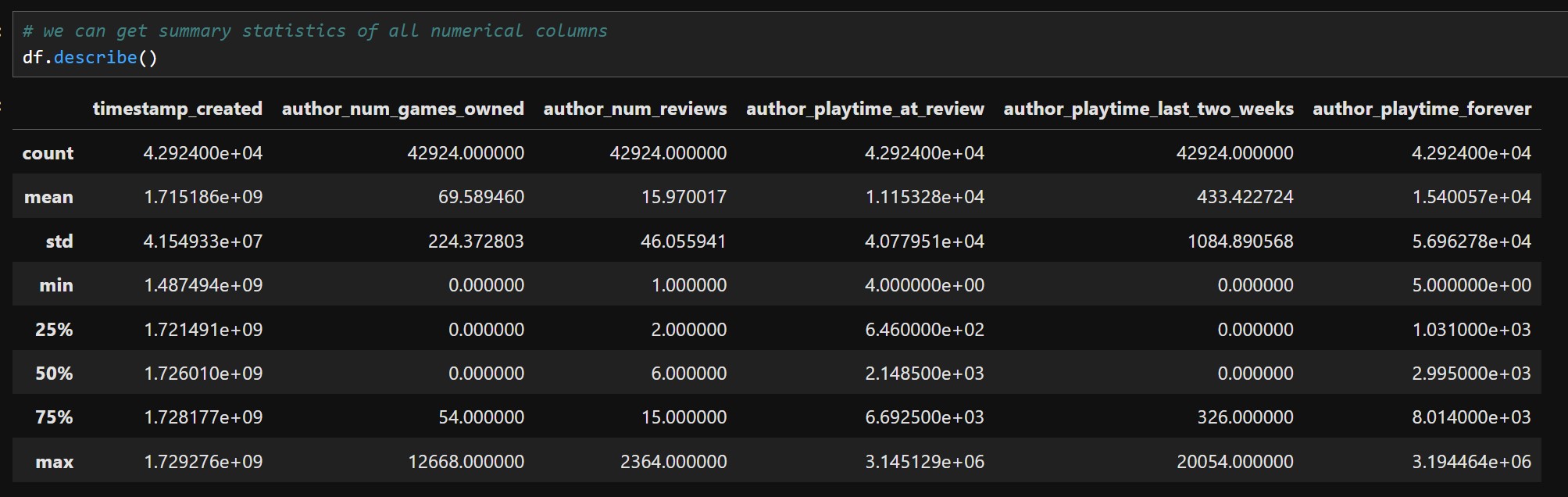
Some common statistics like the mean, standard deviation and other percentile values for all our numerical columns are displayed. We can then see how many positive and negative reviews we have in total in our dataset.

There around 38600 positive reviews and 4300 negative reviews. Now lets look at some specific columns which are of importance to us. Lets check the average review length.

We can see that people use around 172 characters on average in their reviews. We'll look at the average playtime across all the games in hours played next.

The average playtime of the reviewed games is around 185 hours. This seems very high. Does the average gamer really spend this much time on a game? Since our review data includes some multiplayer games where players tend to invest much more time, the data can get skewed. Let us look at median playtime of the reviewed games in hours played.

The median comes out to be around 35 hours. This is more representative of how much time gamers usually spend on a game. Lets check if there's any correlation between playing time and review length.

No significant correlation can be found between the review length and time spent playing that game. So its not like people who play games for longer write longer reviews.
Now its time for us to look at some visualizations to a get a better look at our data.
Median Playtime (in hours) by Game
First let us look at what the median playtime for each game looks like.
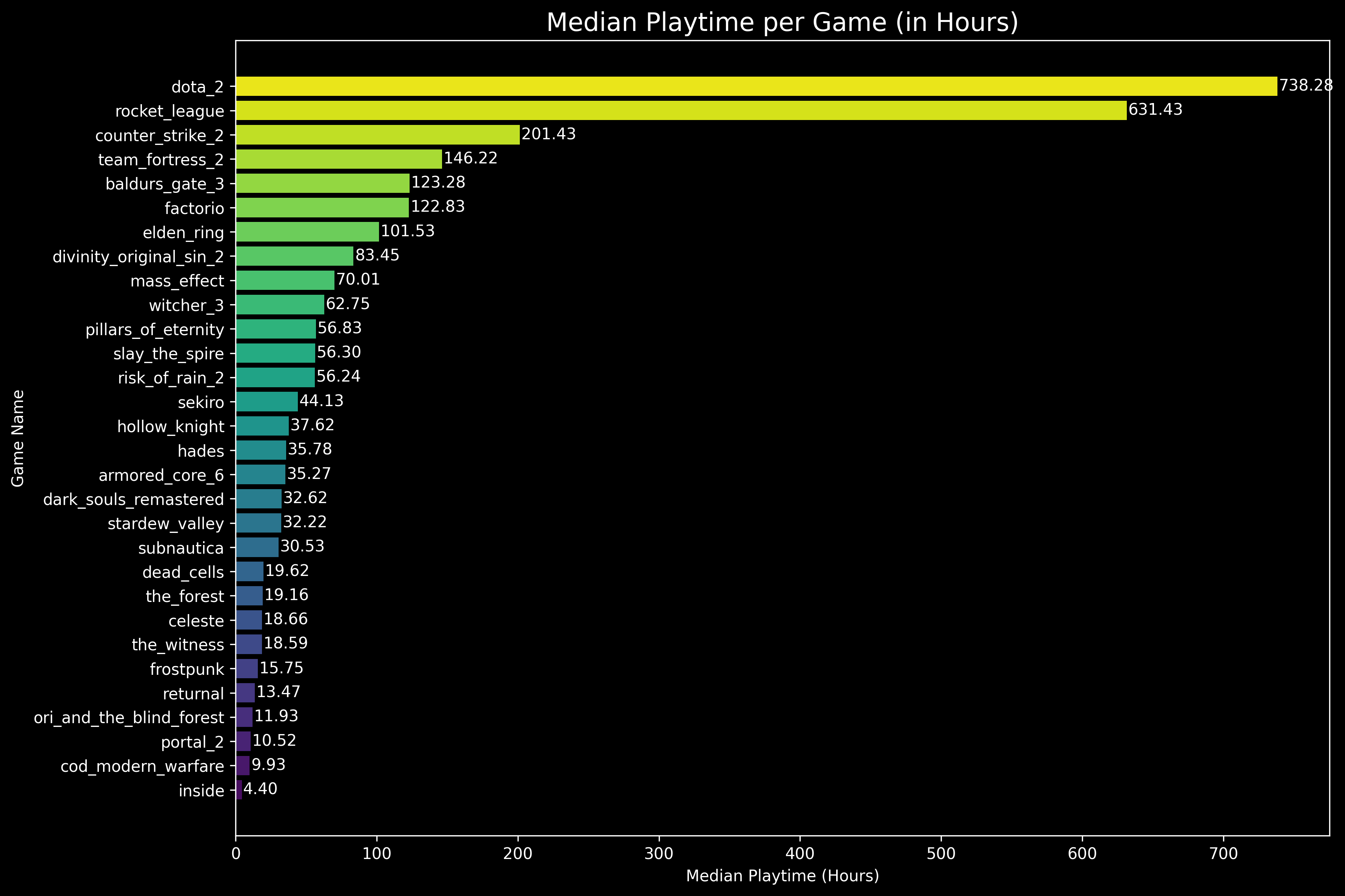
As one would expect, multiplayer PVP games like DOTA 2, Rocket League and Counter Strike 2 have the highest playtimes, where as single player and CO-OP titles like INSIDE, and Portal 2 have shorter playtimes. Call of Duty Modern Warfare has both multiplayer and singleplayer options but still has low playtimes, which might indicate that people tend to drop the game after playing the singleplayer campaign and don't indulge too much into multiplayer.
Average Review Length by Game
Let us see how long the average review is for each game.
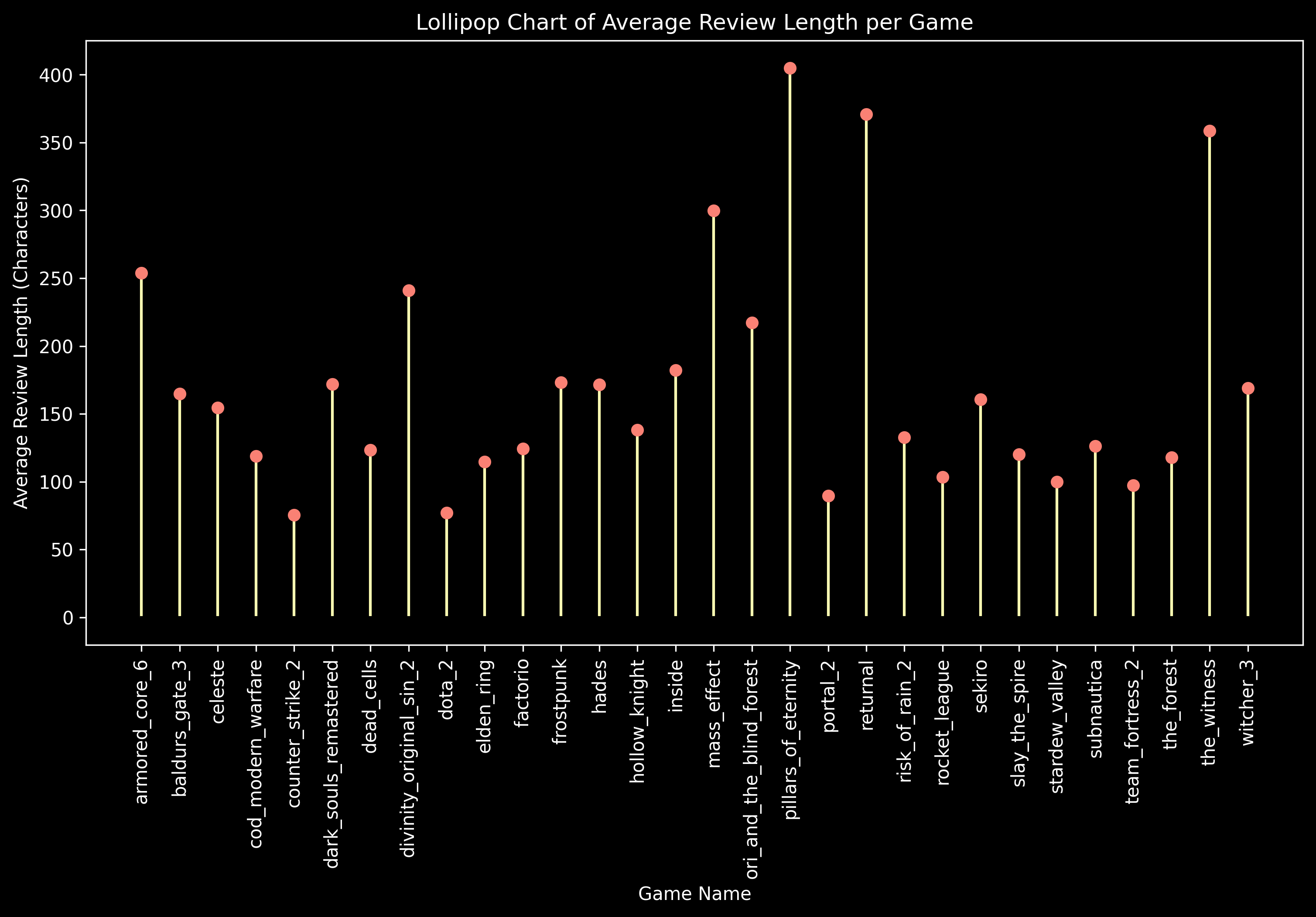
Pillars of Eternity, Returnal and The Witness seem to have the longest reviews while Counter Strike 2 and DOTA 2 have the shortest. Multiplayers games tend to have shorter reviews compared to the others.
Review Sentiment Distribution by Game
We explore the distribution of positive and negative reviews for each game.
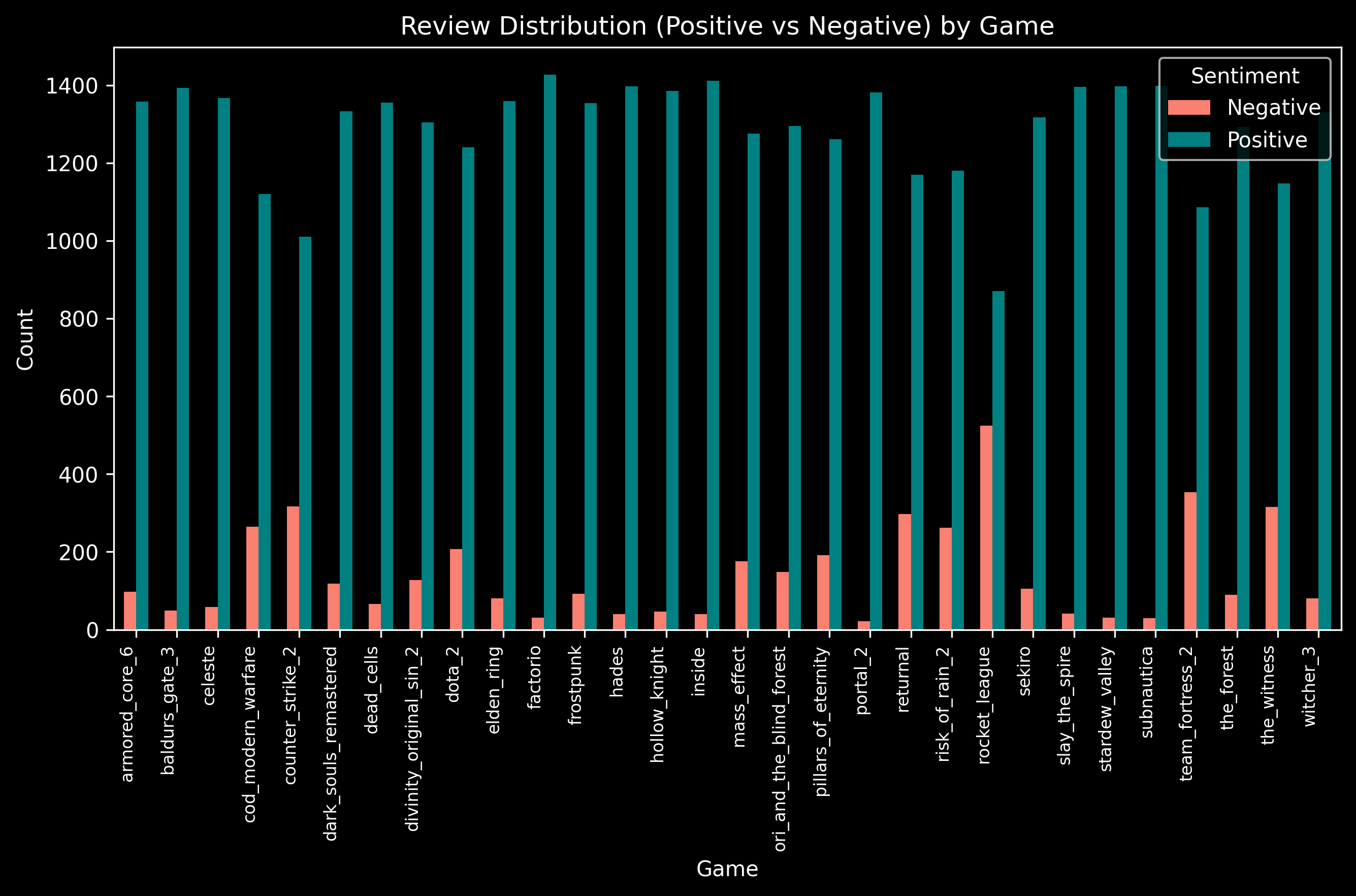
It seems that multiplayer games like Rocket League, Team Fortress 2 and Counter Strike 2 have a higher ratio of negative reviews than other single player and CO-OP games.
Percentage of Positive Reviews by Game
If we want to explore review sentiment of the games further we can see the sorted percentages of positive reviews for the games.
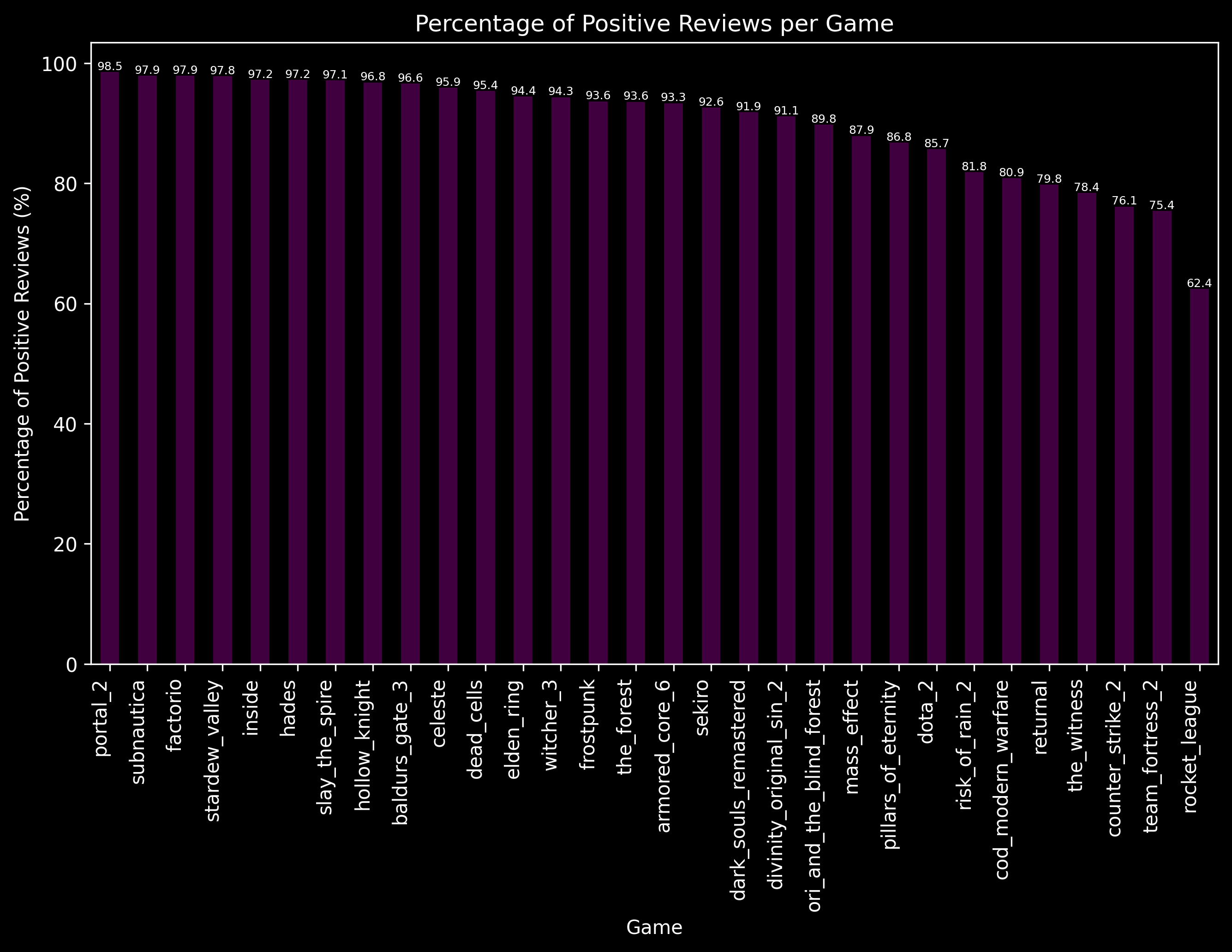
Portal 2, Subnautica and Factorio have the highest percentage of positive reviews wherease Rocket League, Team Fortress 2 and Counter Strike 2 have the least.
Review Length vs Playtime
We can visualize the distribution of the length of the reviews and the playtime while writing the review.
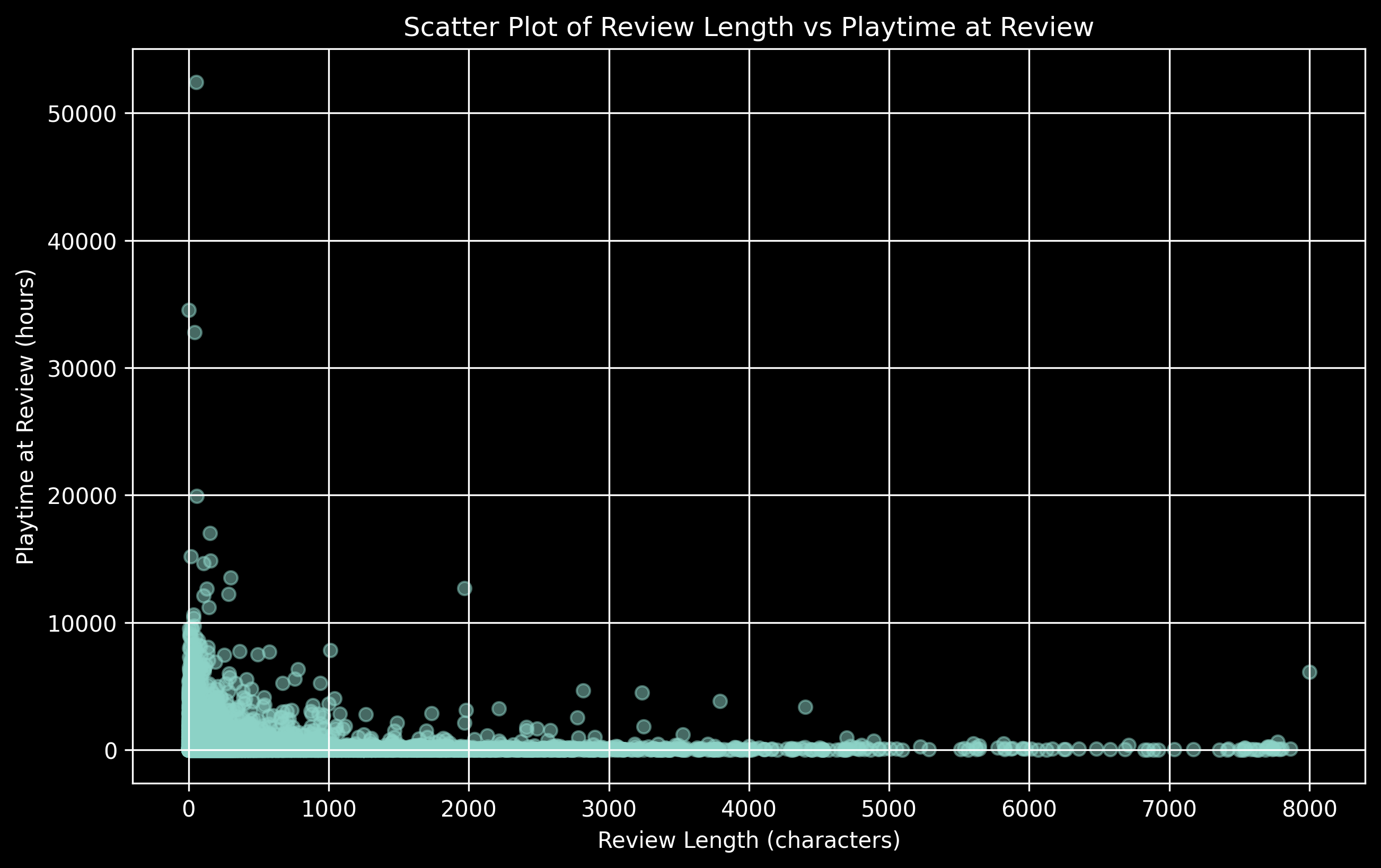
Its hard to identify any specific relationship between the two. But we can also see that both the reviews length and playtime tend to be on the shorter side. We have too many data points and its hard to see the proper distribution. So we'll take a sample of 1000 reviews and then plot them next.
Review Length vs Playtime (Sampled and Zoomed)
We take a sample of 1000 random reviews from our set to get a clearer visual. We also limit our playtime from 0 to 2000 hours and review length from o to 1000 characters as thats where most data points lie.
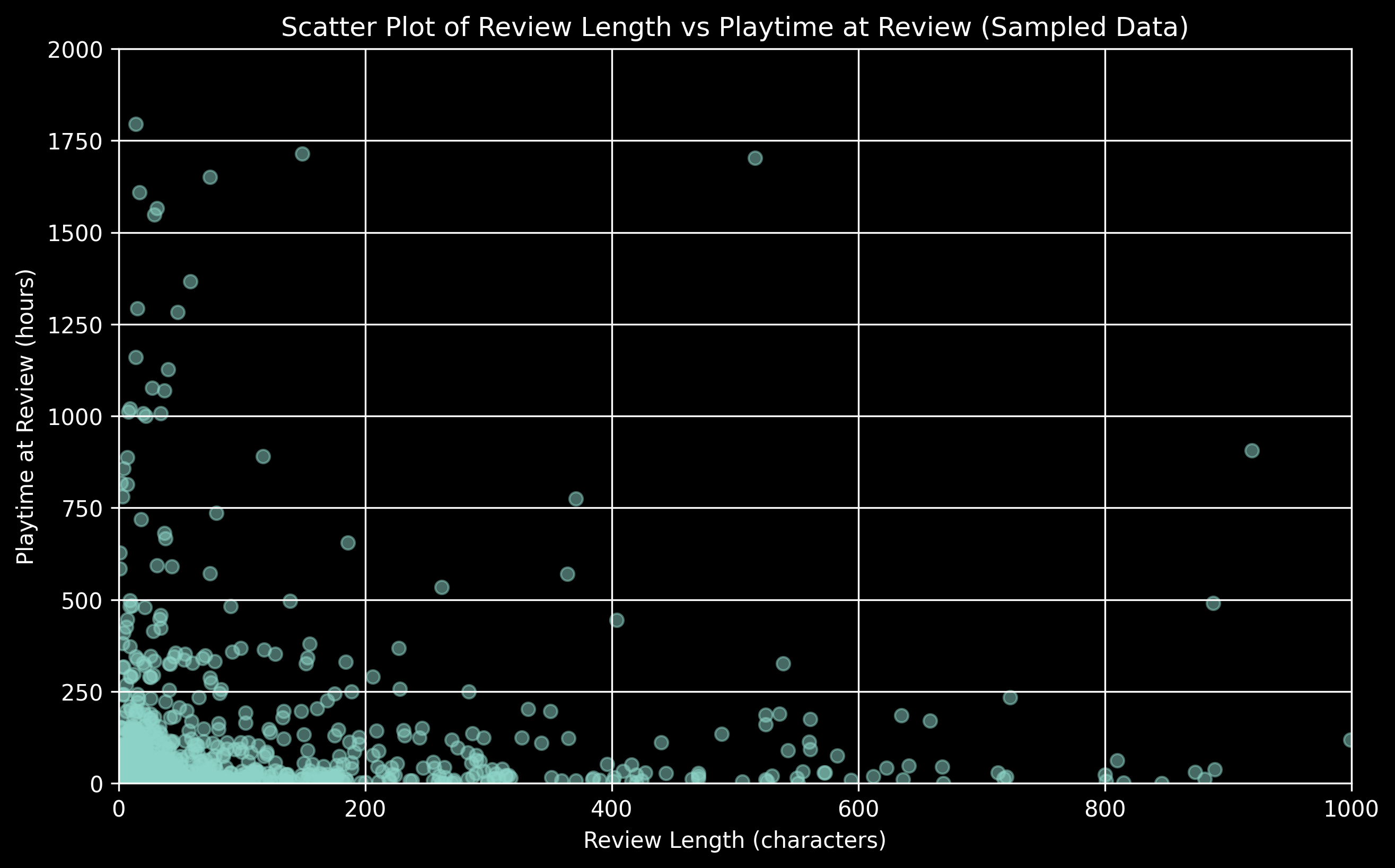
We can see most playtimes are under 250 hours and most reviews are also under 200 characters. People tend to write short reviews for most games they play.
Distribution of When Reviews are Posted
The ratio of playtime at review to the total playtime can give us an idea about when people tend to post their reviews. A small ratio means the reviews were posted very early on when they started playing the game and bigger ratios would mean the reviews were posted closer to the end of their gameplay.
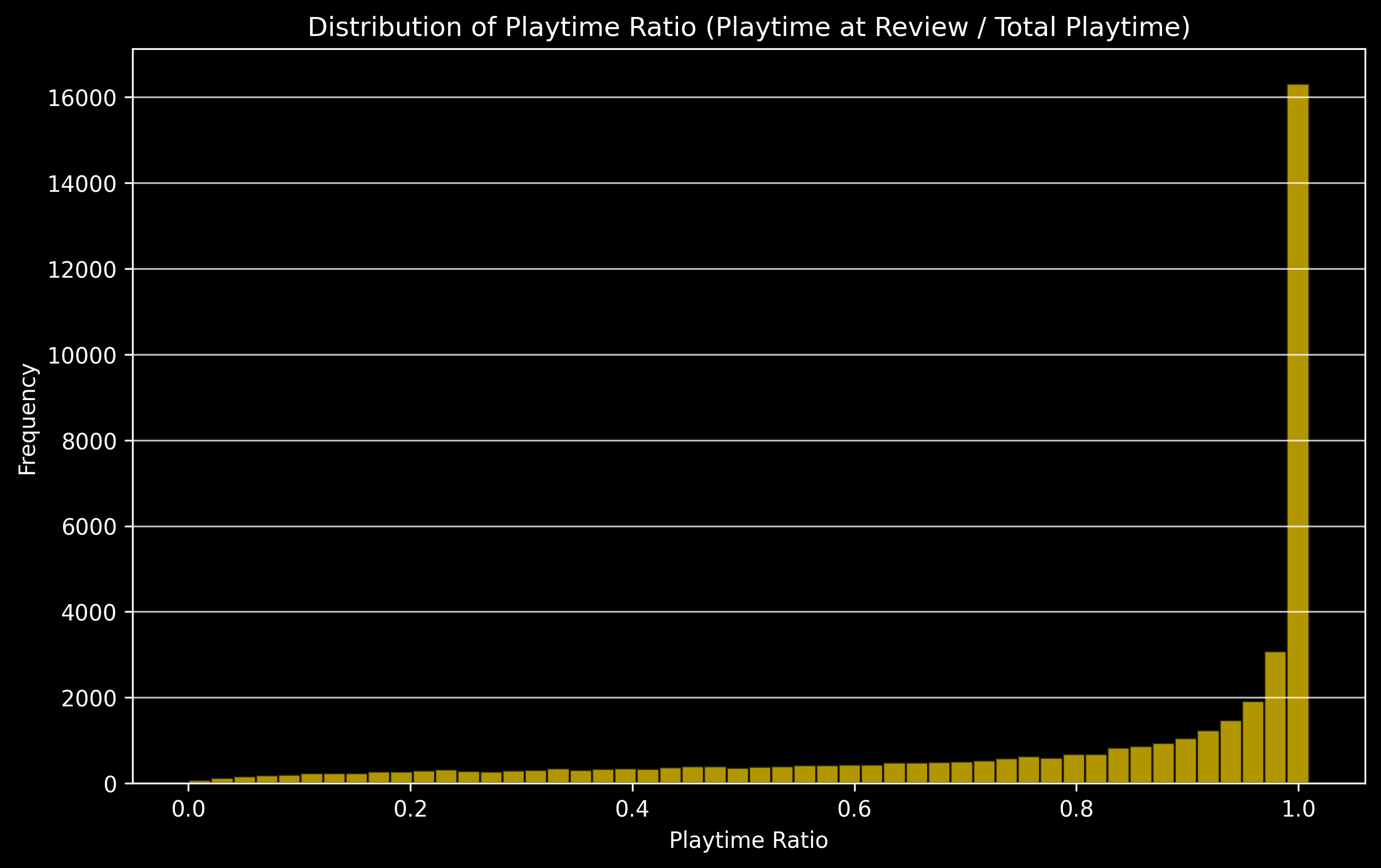
We can see most highest ratios are more common. So most gamers tend to put their reviews closer to the end of their gameplay. This means they are more likely to post the reviews when they have completed the game or they dont play it anymore. Very few people tend to post reviews of games as they're playing them.
Word Cloud of Most frequent Words
Let us visualize what kind of words are most frequently used in our reviews.
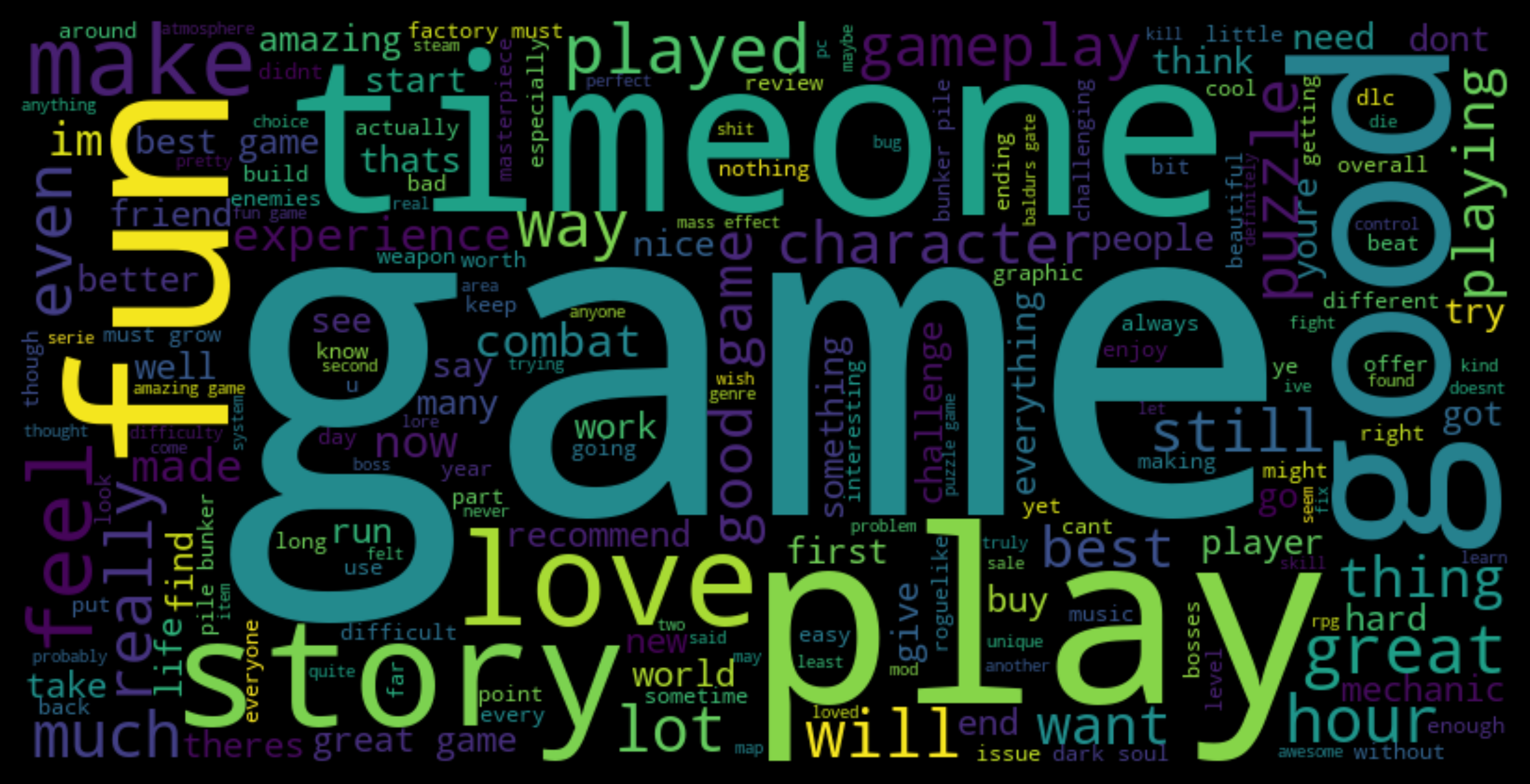
Words like "game", "play", "one", "time", "good", "fun", etc. are very commonly used across our reviews. But we have predominantly positive reviews so words used in those will overshadow words used in negative ones. Let us see if the kind of words used changes across positive and negative reviews
Word Cloud of Most frequent Words across Positive Reviews
First, let us visualize what kind of words are most frequently used in positive reviews.
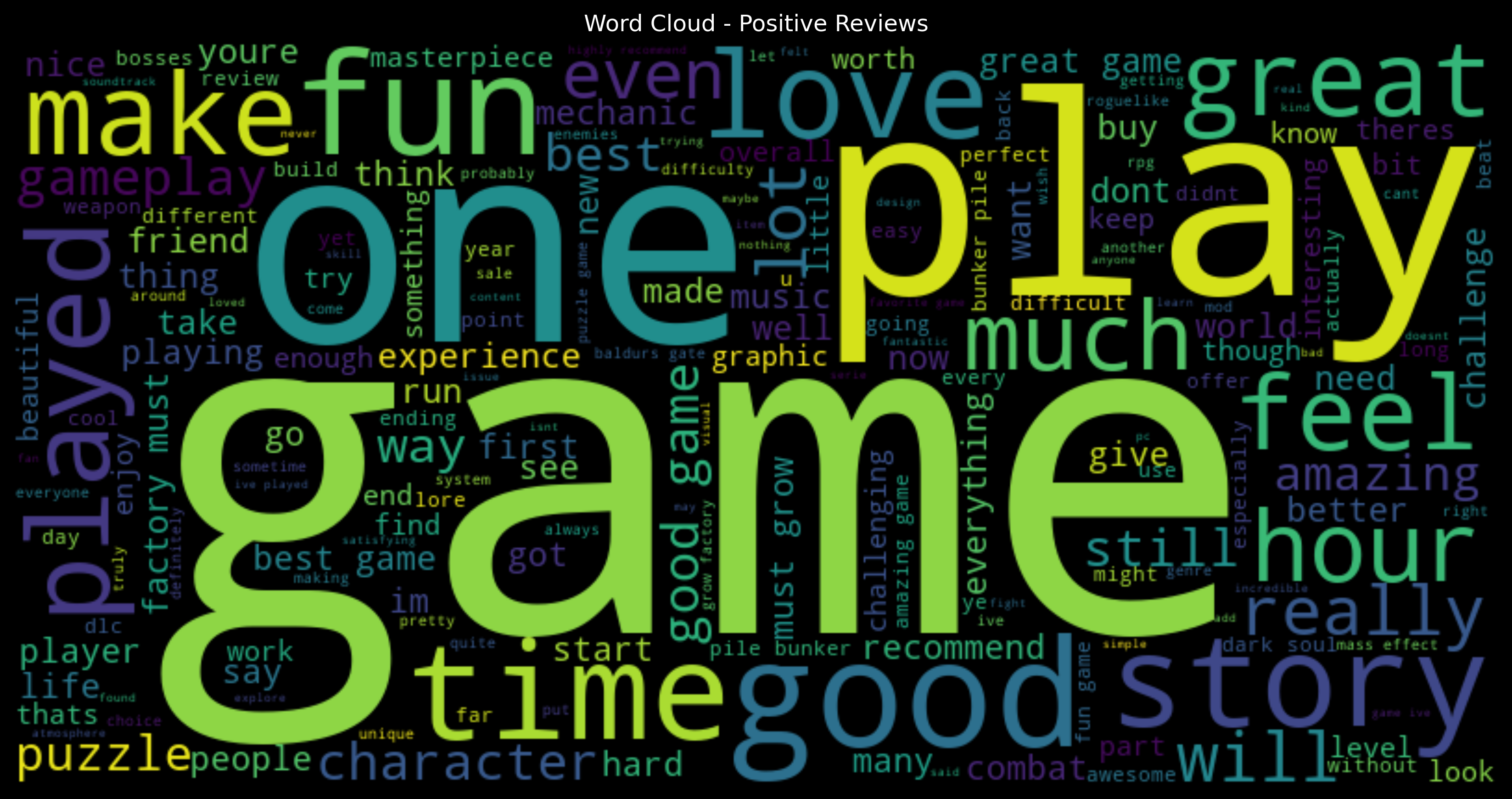
Words like "game", "play", "time", "good", "one", "fun" are very common. These are the same ones which appeared in our overall word cloud. Some more words like "great" and "love" also start appearing more frequently.
Word Cloud of Most frequent Words across Negative Reviews
Next, let us visualize what kind of words are most frequently used in negative reviews.
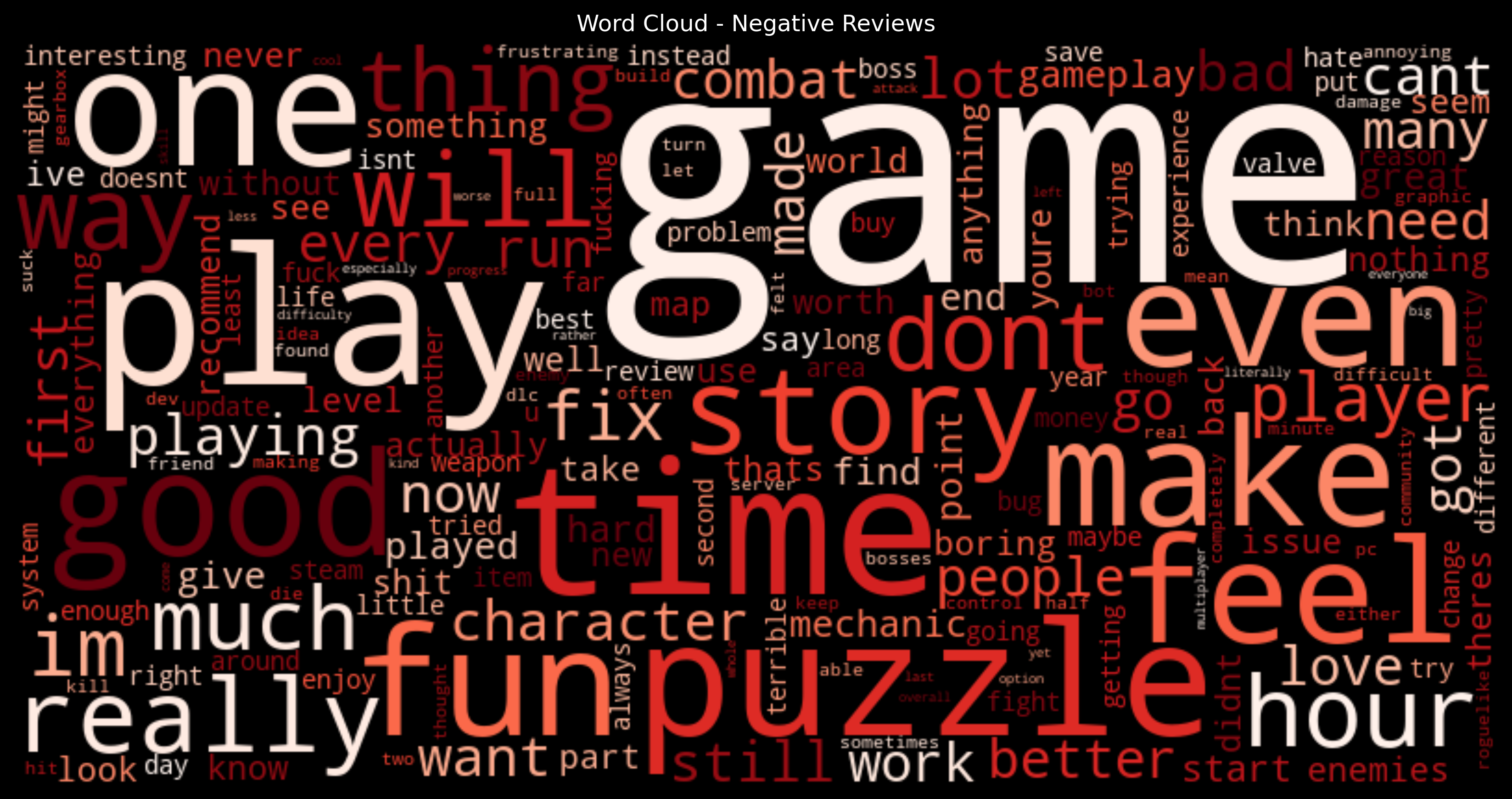
In negative reviews, words like "game", "play", "time", "one" are still the most common. Words like "great" and "love" become much less frequent.
Review Length Distribution by Review Sentiment
The review length for each type of sentiment is analyzed next.
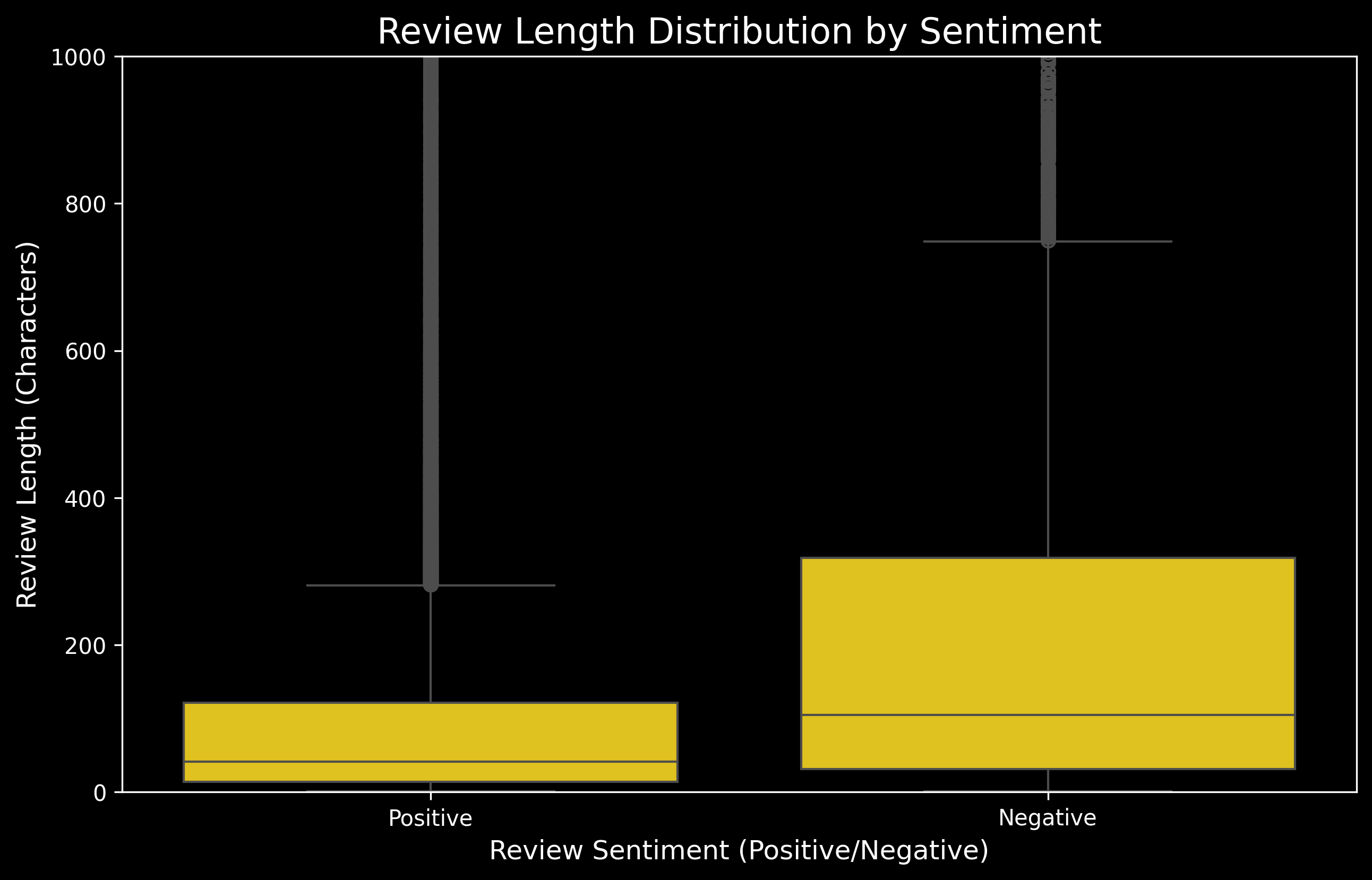
We limit our review length to upto 1000 characters as we have lot of outliers. Positive Reviews tend to have much lesser median number of charcaters. Negative reviews tend to be longer with a wider interquartile range.
Playtime distribution by Review Sentiment
We now explore the distribution of playtime of two sentiments of reviews.
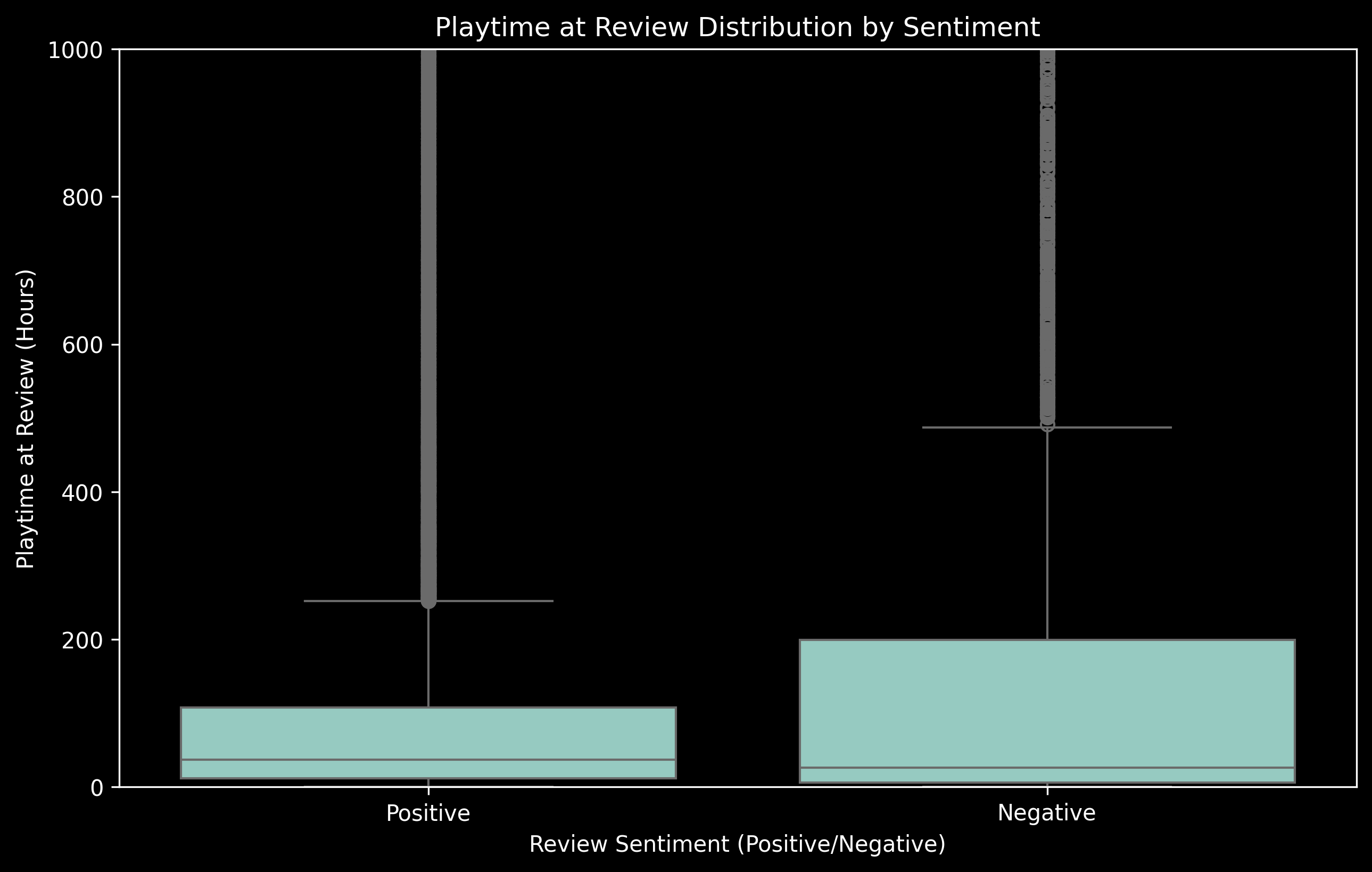
Both types of reviews have a lot of outliers so we limit our playtime to upto 1000. Positive Reviews tend to have a higher median playtime compared to negative reviews. However negative reviews have a much wider interquartile range of playtimes.
Frequency of Positive and Negative Reviews with Playtime
Finally, let us see the frequency of negative and positive reviews for different ranges of playtime.
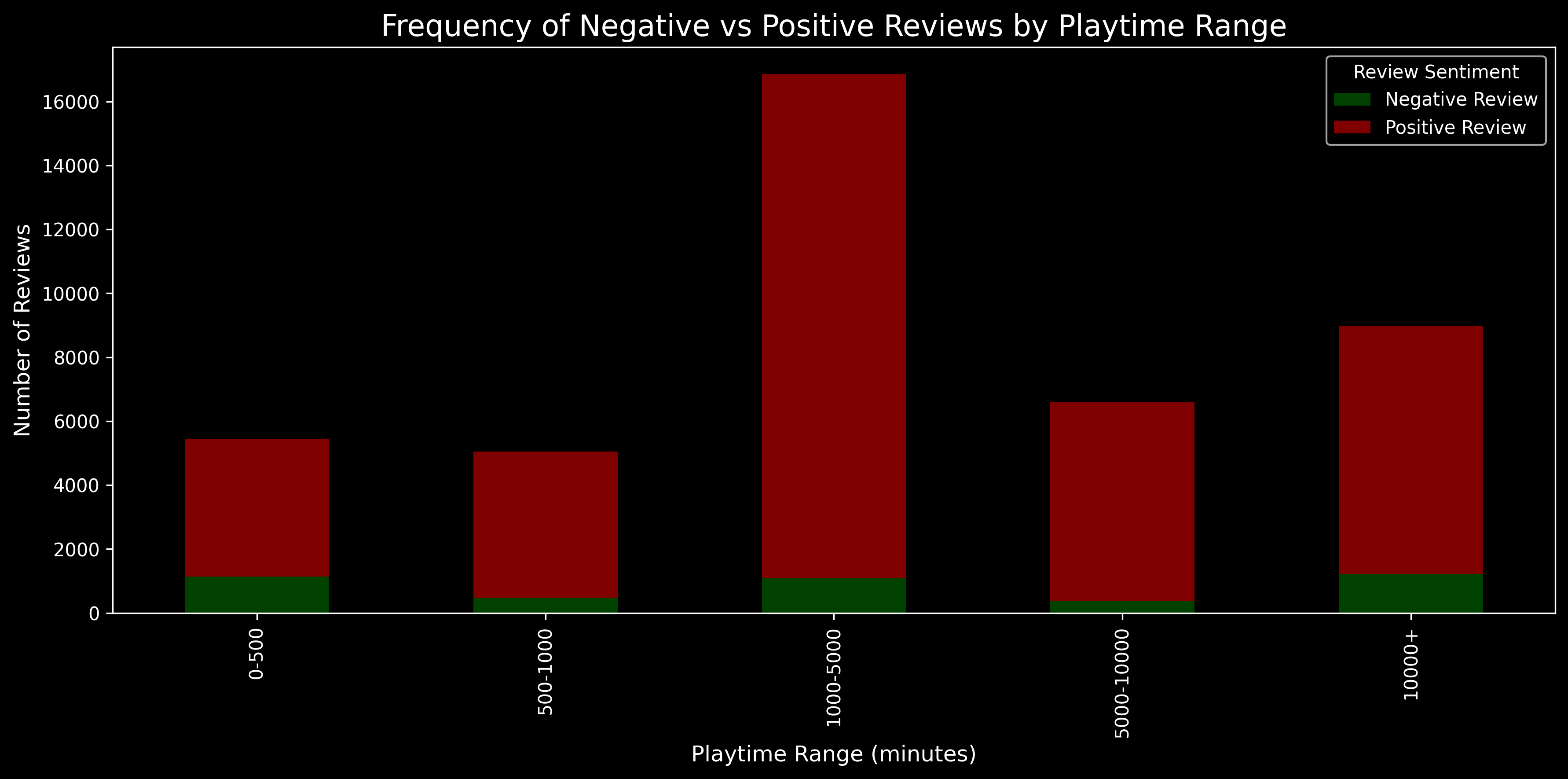
Shorter playtimes have a higher ratio of negative to positive reviews compared to longer reviews. As evident from the median, people tend to play for shorter times when they leave a negative review. The playtimes between 1000 to 5000 minutes has the most number of reviews.
For a detailed walkthrough of our data exploration process and visualizations, you can view our full Jupyter notebook here.
Feature Engineering
On the cleaned dataset, we will do some more preprocessing and feature engineering. The cleaned data looked like this:
We use the nltk package to get a set of stop words. Stop words are frequently used words (like "and," "the," "is") that generally do not add significant meaning to text analysis. We will remove these words from our review. The review column now looks like this:
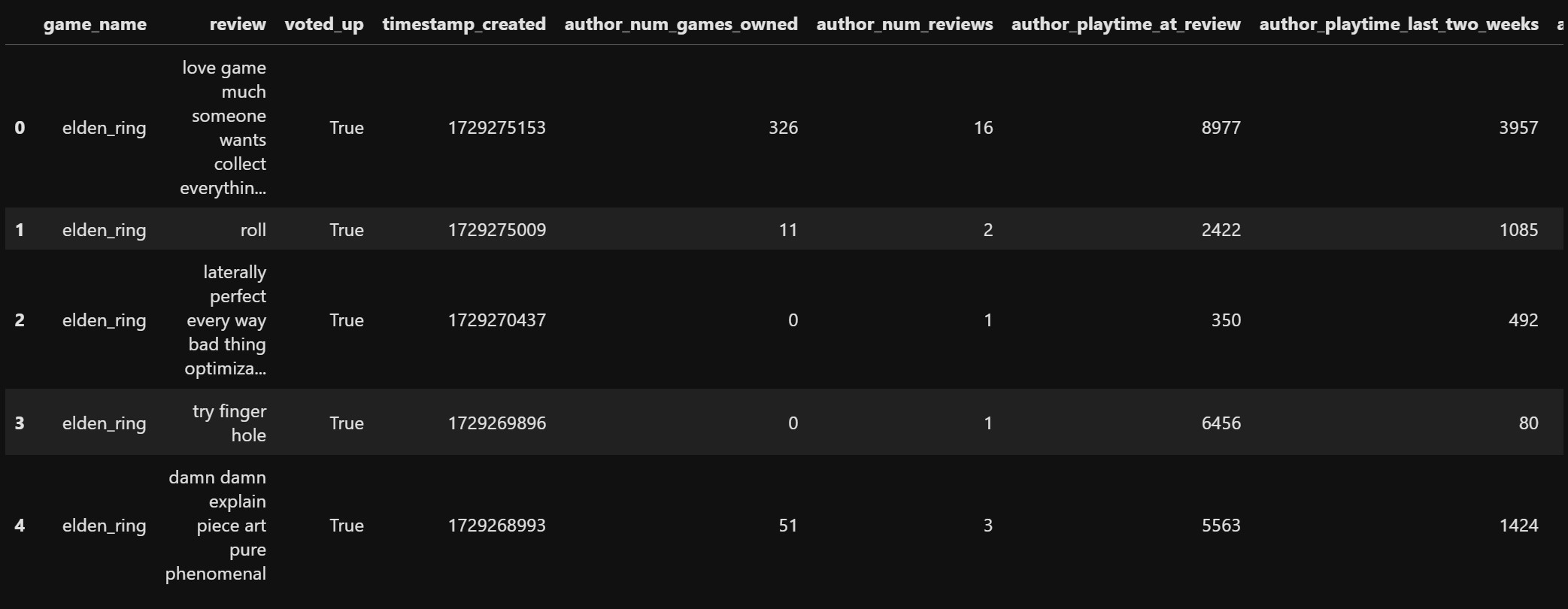
We will define a set of words which are commonly used to express difficulty in the gaming world. These include:
'formidable', 'galaxybrain', 'merciless', 'tiresome', 'impossible',
'intense', 'punishing', '2ez', 'moderate', 'smurfing', 'standard', 'daunting', 'bonkers', 'harsh', 'noobfriendly',
'git', '2easy', 'exhausting', 'overwhelming', 'busted', 'chill', 'ggez', 'accessible', 'filthycasual', 'relentless',
'hefty', 'hardcore', 'tricky', 'casual', 'ez', 'ultrahard', 'boomerfriendly', 'masochistic', 'fair', 'frustrating', 'getgood',
'megahard', 'relaxing', 'rigorous', 'sweaty', 'extreme', 'reasonable', 'steady', 'robust', 'soulcrushing', 'casul', 'broken', 'taxing',
'hard', 'strict', 'straightforward', 'savage', 'bigbrain', 'technical', 'insane', 'demonic', 'easymode', 'omegahard', 'skillcheck', 'deadly',
'breezy', 'diabolical', 'issue', 'skillbased', 'expertlevel', 'tryhard', 'challenging', 'touchgrass', 'rekted', 'gud', 'nolife', 'touch grass',
'complex', 'forgiving', 'zoomer', 'ruthless', 'fierce', 'backbreaking', 'tortuous', 'tough', 'intensive', 'maddening', 'wicked', 'rageinducing',
'beastly', 'ridiculous', 'progamer', 'mindbending', 'basic', 'troublesome', 'hardmode', 'gentle', 'demanding', 'thorough', 'vicious', 'omegalul',
'skill', 'crushing', 'ezpz', 'unbearable', 'brutal', 'middleground', 'rage', 'painful', 'rip', 'evenpaced', 'gigahard', 'crazy', 'kekw', 'skill check',
'grueling', 'gitgud', 'laidback', 'nightmarish', 'gradual', 'simple', 'stressful', 'unforgiving', 'balanced', 'strategic', 'rekt', 'severe', 'scrubfriendly',
'difficult', 'skillissue', 'oppressive', 'normiefriendly', 'manageable', 'beginnerfriendly', 'rough', 'hellish'
Using this set of words, we will derive a new feature to count the number of words used to describe difficulty.
This will later help us identify which reviews mention difficulty and which don't.
From this we will extract another binary feature to classify which reviews mention difficulty (i.e. difficulty word count >0) and which don't.
We will also derive a new feature called review length by taking the length of the review column.
The data after these features are added looks like this:
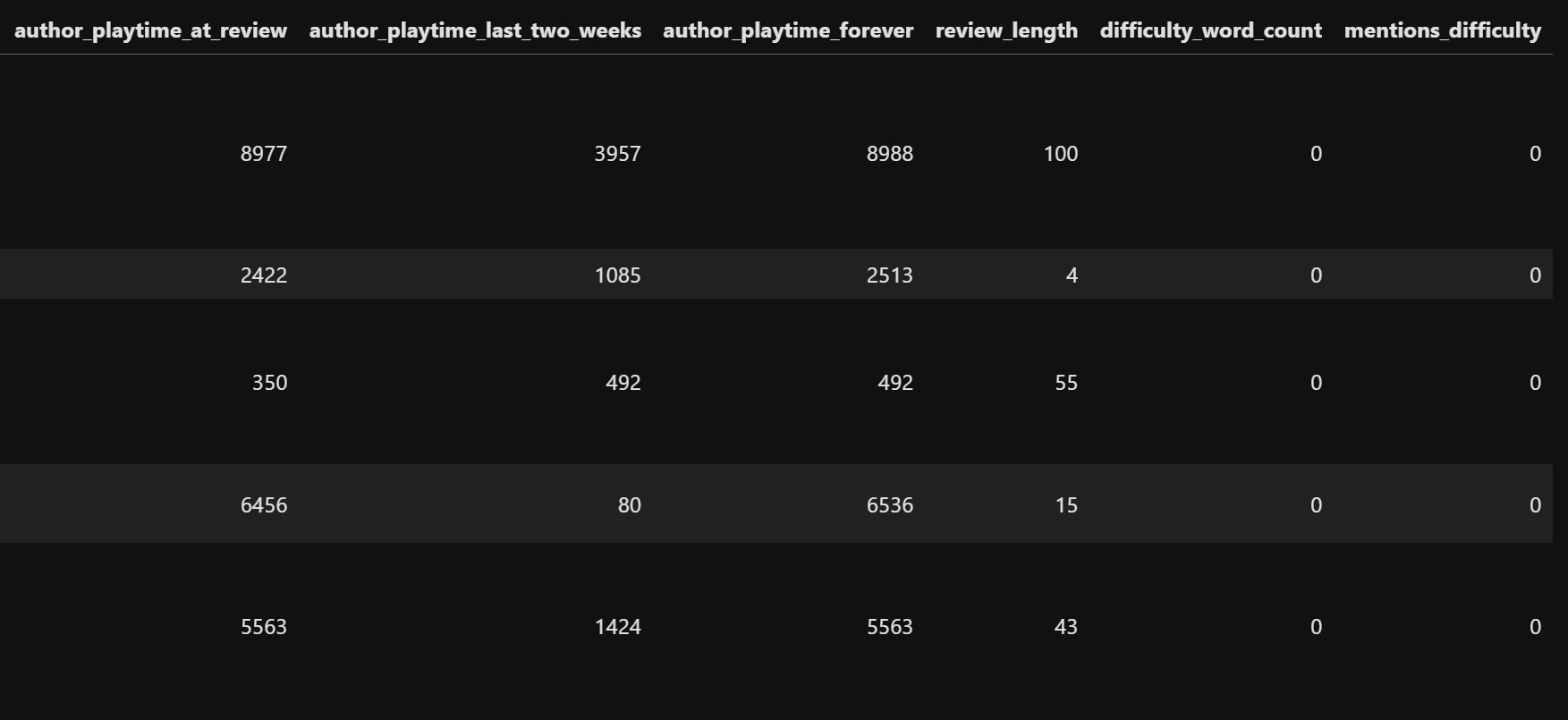
Next, we will define a mapping with games and a list of its genres. Using this we would be creating a new feature for genres. The genre mapping for each game is the following:
- elden_ring : ['soulslike', 'open_world', 'rpg', 'third_person']
- sekiro : ['soulslike', 'action', 'adventure', 'third_person']
- dark_souls_remastered : ['soulslike', 'action', 'rpg', 'third_person']
- armored_core_6 : ['third_person', 'soulslike', 'action']/li>
- hollow_knight : ['metroidvania', 'platformer', 'soulslike', '2d']
- hades : ['roguelike', 'action']
- dead_cells : ['action', 'adventure', 'roguelike', 'metroidvania', '2d']
- slay_the_spire : ['roguelike', 'deckbuilding', 'turn_based']
- returnal : ['action', 'roguelike', 'co_op', 'third_person', 'shooter']
- risk_of_rain_2 : ['action', 'roguelike', 'third_person', 'co_op', 'shooter']
- witcher_3 : ['open_world', 'rpg', 'adventure', 'fantasy']
- mass_effect : ['rpg', 'action', 'third_person', 'shooter']
- divinity_original_sin_2 : ['turn_based', 'rpg', 'strategy', 'crpg', 'fantasy']
- baldurs_gate_3 : ['turn_based', 'rpg', 'crpg', 'fantasy']
- pillars_of_eternity : ['rpg', 'crpg', 'fantasy']
- portal_2 : ['platformer', 'puzzle', 'first_person']
- the_witness : ['puzzle', 'first_person', 'open_world']
- celeste : ['platformer', '2d']
- ori_and_the_blind_forest : ['platformer', '2d', 'metroidvania']
- inside : ['puzzle', 'platformer', '2d']
- stardew_valley : ['2d', 'sandbox', 'crafting', 'simulation']
- factorio : ['2d', 'sandbox', 'crafting', 'simulation', 'base_building', 'strategy', 'survival']
- frostpunk : ['base_building', 'strategy', 'survival', 'simulation']
- the_forest : ['survival', 'open_world', 'crafting', 'first_person']
- subnautica : ['survival', 'open_world', 'crafting', 'first_person']
- cod_modern_warfare : ['action', 'first_person', 'shooter', 'multiplayer']
- rocket_league : ['multiplayer', 'competitive']
- counter_strike_2 : ['multiplayer', 'competitive', 'first_person', 'shooter']
- team_fortress_2 : ['first_person', 'shooter', 'multiplayer']
- dota_2 : ['multiplayer', 'strategy', 'competitive']
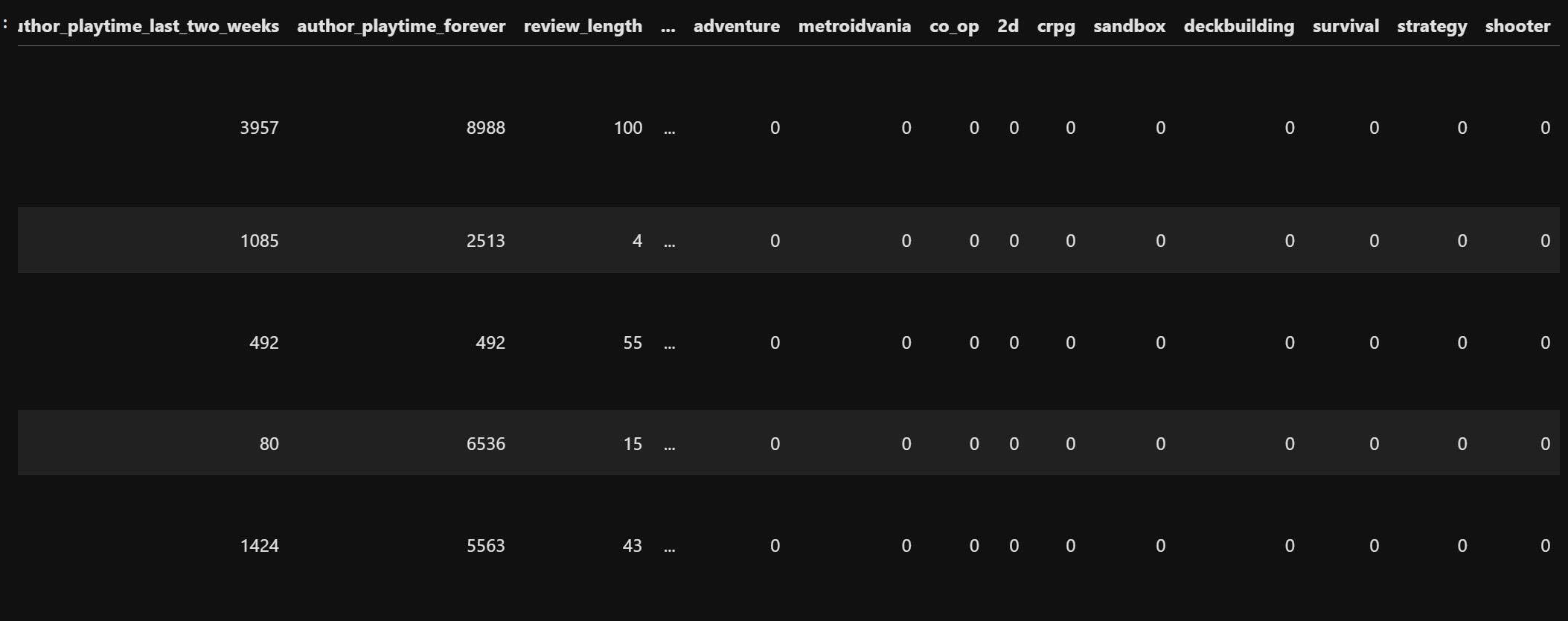
We will directly one hot encode this genre feature instead of creating a single column first.
We will initialize everything to 0 first and then for every game whichever genres were mapped, those columns are made 1.
The new data looks like has these new features now:
We will extract another feature which classified players as “beginner”, “intermediate” or “experienced”. For the specific game mentioned in the review, we will classify it as beginner if the author’s playtime is lower than the lower quartile playtime for that game. If the author’s playtime is greater than upper quartile playtime or if their number of games owned by them is greater than 30 then the record would be classified as experienced. If the number of games owned is greater than 10 and the playtime is above the median, then they would be classified as experienced as well. For other cases, they are classified as intermediate. It looks like this:
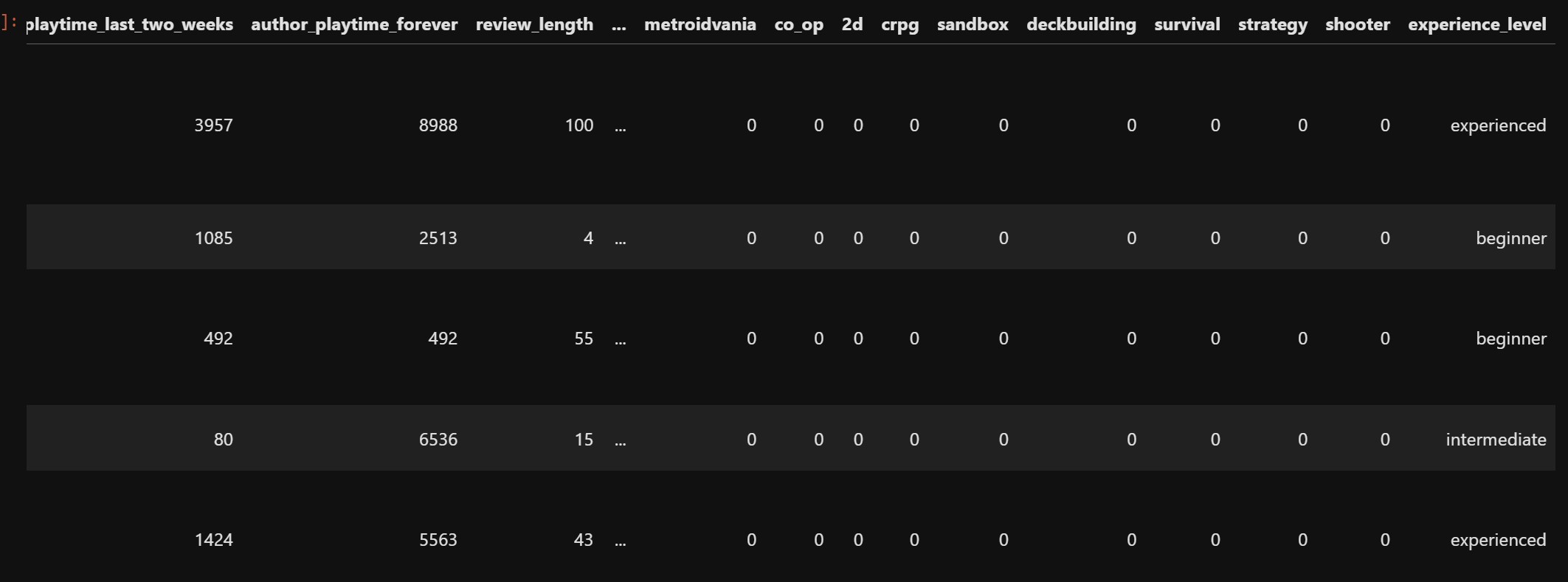
We will one hot encode this column. The new data looks like this:
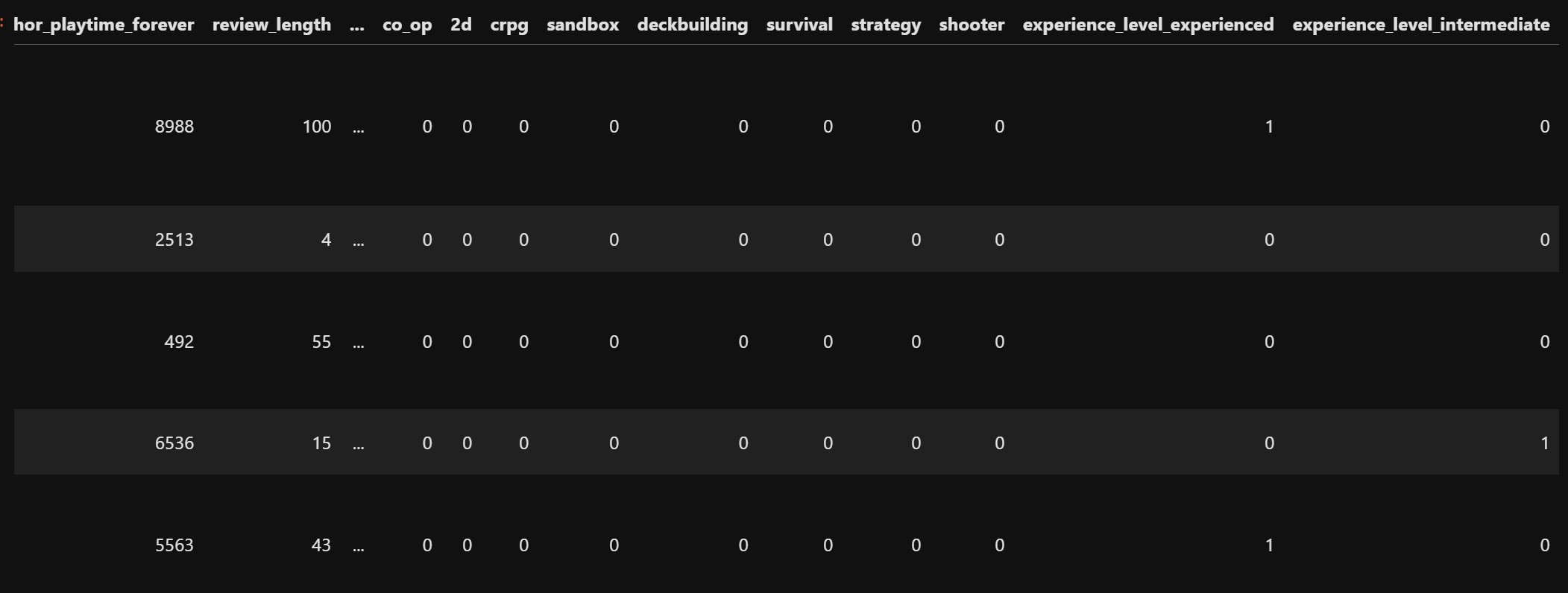
Text reviews (review) contain detailed feedback, but their raw form is difficult for machine learning models to interpret directly.
By extracting a sentiment score, we provide a numerical representation of the review’s polarity, making it easier for the model to process.
VADER (Valence Aware Dictionary and sEntiment Reasoner) is a pre-trained rule-based sentiment analysis tool from the NLTK library, designed to handle social media text and other short reviews.
It provides four sentiment scores for a given text:
- Positive: Proportion of positive words
- Neutral: Proportion of neutral words
- Negative: Proportion of negative words
- Compound: A single aggregated score that represents the overall sentiment of the text
For each review in the review column, we applied sia.polarity_scores(x) to compute sentiment scores. We selected the compound score, which is a normalized value between -1 (most negative) and 1 (most positive). This value is stored as the new column “sentiment_score”. The data looks like this now:
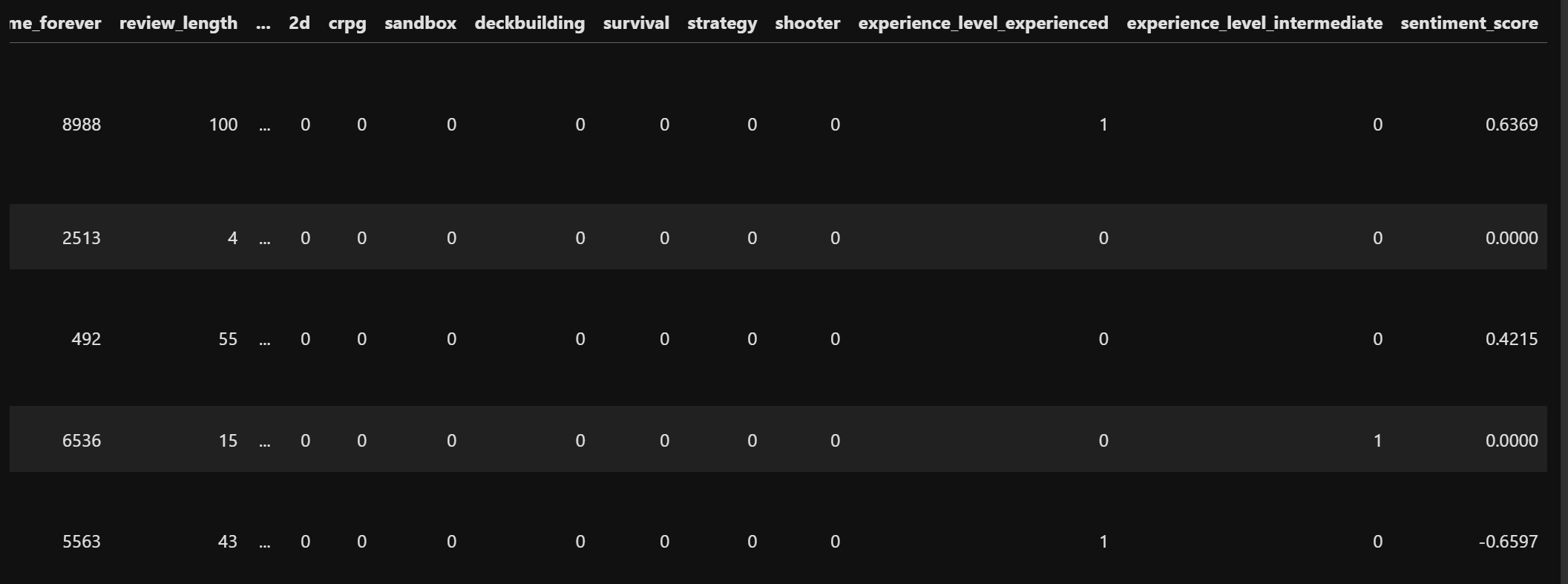
This processsed dataset ready to be implemented into models finally looks like this:

We save this updated dataset to a csv file. For a detailed walkthrough of our feature engineering process, you can view our full Jupyter notebook here.