Conclusion
Project Summary
Our project aimed to explore how players perceive and discuss video game difficulty through their reviews. Using a dataset of 43,000 reviews from 30 diverse games, we analyzed the relationship between game difficulty and player sentiment across genres, metadata, and review content. Our research questions were addressed using a mix of machine learning models, statistical analyses, and visualizations.
Key Findings
Review Sentiment:
Positive reviews were predicted effectively with high accuracy (93%) and an F1 score of 96%, though identifying negative reviews remained challenging.
Genres and Difficulty Mentions:
Attempts to predict difficulty mentions using game genres showed poor results, with models achieving only 57% accuracy and an F1 score of 30% for difficulty mentions. This suggests a weak relationship between genres and difficulty mentions. "Co-op" and "metroidvania" games had the highest proportion of reviews mentioning difficulty, at 18%+, while "competitive" and "multiplayer" games had the lowest proportions, at 7-8%. These mentions included discussions of both “hard” and “easy” difficulty.
Player Experience and Sentiment:
Beginner players gave lower sentiment scores compared to intermediate and experienced players, with differences confirmed to be statistically significant by our tests. Players with shorter playtimes (less than 5 hours) were more likely to mention difficulty, with mentions decreasing as playtime increased.
Summary of Modelling Results
Accuracy of the Models
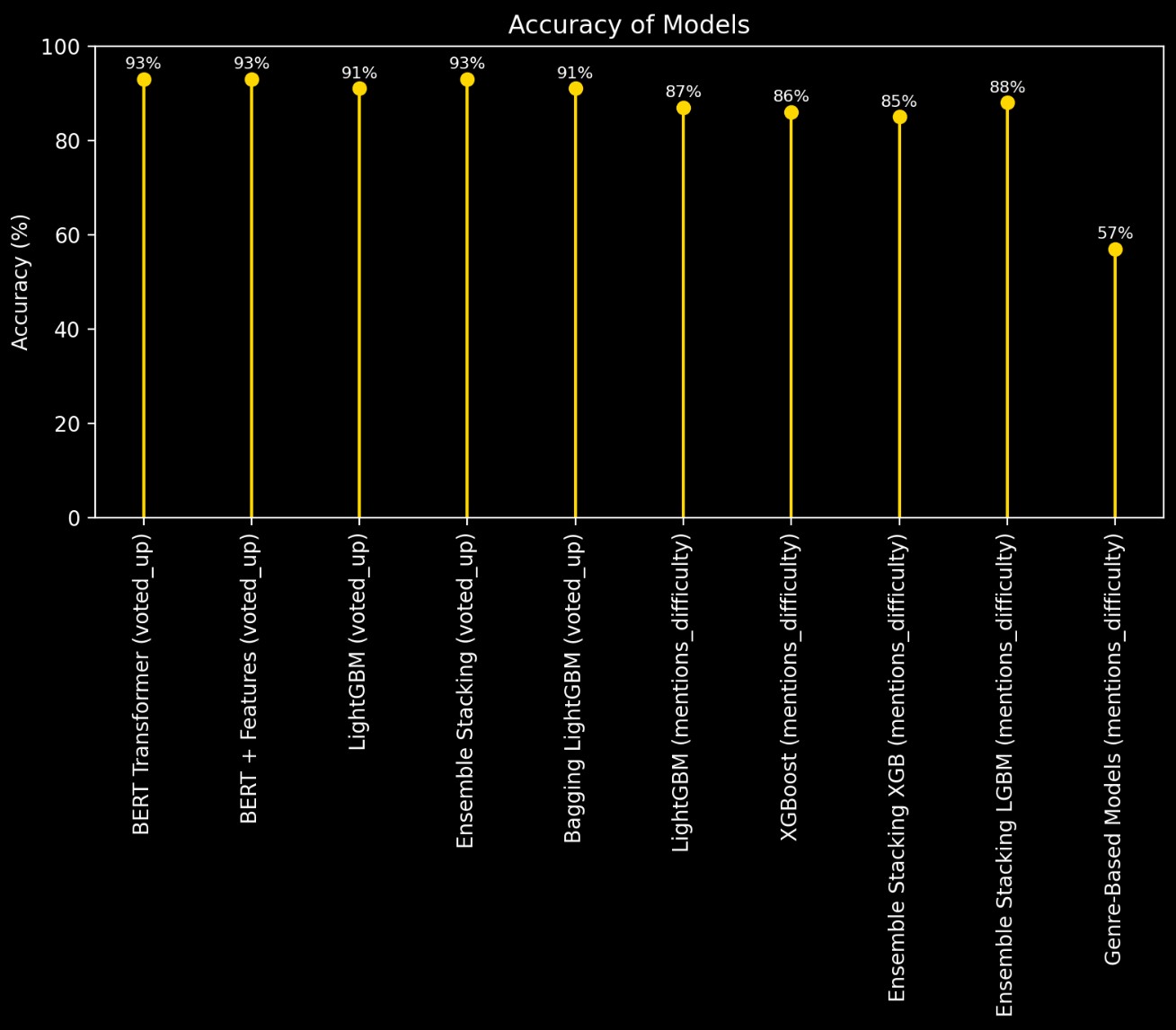
This chart highlights the overall accuracy of the models used in the project. The highest accuracy (93%) was achieved by several models, including the BERT-based models and ensemble stacking models for predicting whether a review is positive. However, the genre-based models for predicting difficulty mentions struggled, with an accuracy of just 57%, underscoring the challenge of modeling this relationship.
Class Specific and Macro Average F1 Scores
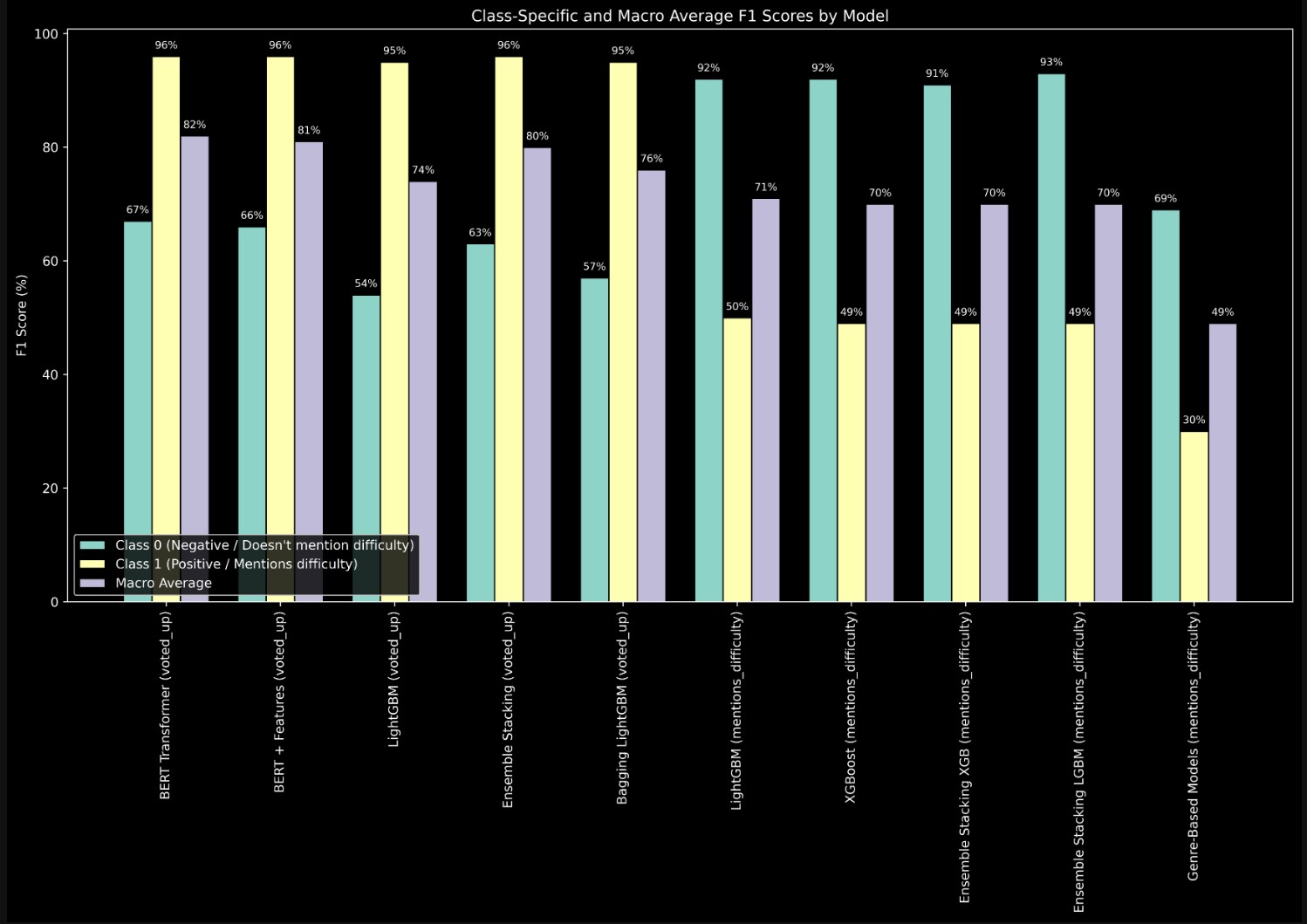
The grouped bar chart provides a deeper look into the models' performance for individual classes (Class 0: Negative/No Difficulty Mention and Class 1: Positive/Difficulty Mention) and their macro-average F1 scores. While the majority class showed strong F1 scores (up to 96%), The minority class often lagged behind, with F1 scores as low as 30% for some tasks. This discrepancy highlights the impact of class imbalance and the need for more nuanced modeling approaches.
Addressing Research Questions
1. Can we predict whether a review is positive based on its content?
Our models could predict positive reviews well, with high accuracy and strong performance for positive feedback. However, they struggled with identifying negative reviews, often missing key patterns in this category. This highlights the challenges of balancing predictions for both positive and negative reviews.
2. Can genres of games indicate whether a player mentions difficulty?
We tried to use game genres to predict if a review would mention difficulty, but the results showed no strong connection between the two. This suggests that difficulty mentions cannot be reliably predicted based on genre alone.
3. Which genres are most associated with mentions of difficulty in reviews?
We found that "co-op" and "metroidvania" games were the most likely to have reviews mentioning difficulty, while "competitive" and "multiplayer" games were the least likely. However, these mentions of difficulty include both positive and negative discussions, such as difficulty being "too easy" or "too hard."
4. How does the sentiment score distribution differ between genres?
Genres like "competitive" and "multiplayer" had the lowest average review sentiment, suggesting more critical feedback. In contrast, "crpg" and "fantasy" games had the highest, reflecting more positive sentiment from players in those genres.
5. Can we model if a review mentions difficulty using review meta-data?
We explored using details like review length and sentiment score to predict difficulty mentions. While our models achieved decent accuracy, they struggled to identify reviews mentioning difficulty with enough consistency, especially for less common patterns.
6. Does the player's experience level affect their sentiment towards game difficulty?
Players with less experience (beginners) were more likely to leave negative feedback about difficulty, while more experienced players tended to give higher ratings. The difference was most noticeable between beginners and the other two groups (intermediate and experienced players).
7. How does the number of games owned by a player correlate with their review sentiment?
We found no meaningful relationship between how many games a player owns and how they feel about a game’s difficulty. Library size doesn’t appear to affect how players rate or review games.
8. Do reviews mentioning difficulty tend to be more positive or negative overall?
Most reviews mentioning difficulty were positive, with higher sentiment scores. This suggests players often enjoy discussing challenging games, though it doesn’t necessarily mean all mentions were about “hard” difficulty.
9. Are difficulty mentions more common in reviews with shorter playtimes compared to longer playtimes?
Yes, we saw that reviews mentioning difficulty were more common among players with shorter playtimes, especially those with less than 5 hours. As playtime increased, these mentions became less frequent, possibly indicating initial impressions play a large role.
10. What are the most commonly expressed words in negative reviews mentioning difficulty?
Words like "game," "play," and "time" were the most common in negative reviews about difficulty. However, these words are quite general, and more focused analysis would be needed to understand specific frustrations.
Significance of Findings
For Developers:
These findings provide actionable insights to tailor game difficulty to target audiences. Developers can design difficulty settings or onboarding processes that cater to both beginner and experienced players.
For Players:
Players can use this analysis to identify games suited to their preferences and skill levels, avoiding potential frustration or finding rewarding challenges.
For Platforms:
Gaming platforms can implement smarter recommendation systems that consider player sentiment and difficulty perception.
Potential Use Cases
Game Balancing:
Developers can adjust difficulty settings or add dynamic difficulty adjustments based on player feedback trends.
Player Insights:
Gaming platforms can use these findings to recommend games that align with individual preferences.
Community Engagement:
Insights about difficulty-related frustrations can help developers address player concerns in updates or sequels.
Limitations and Future Improvements
In-Game Metrics:
Our analysis relied heavily on metadata such as playtime and the number of games owned, which do not fully capture a player's in-game behavior or progression. Including additional in-game metrics, such as achievement progression, difficulty settings, or completion rates, could help us better understand how players perceive and respond to game difficulty over time.
Modeling Challenges:
The models faced difficulties with imbalanced data, leading to weaker performance for underrepresented classes such as negative reviews or difficulty mentions. Simpler models like Decision Trees also failed to capture meaningful relationships, particularly between genres and difficulty mentions. Future work could address these issues using more advanced data balancing techniques, gaming-specific fine-tuning for NLP models, and hybrid approaches that combine advanced NLP with rule-based or ensemble methods.
Player Metadata and Experience:
Models using player metadata, such as playtime and number of games owned, showed moderate success in predicting difficulty mentions but struggled to consistently capture nuanced patterns. Adding features such as solo versus co-op gameplay styles or player-specific behaviors could enhance the predictive power of metadata-based models and provide a more complete picture of player preferences.